3.2. Ajustar los hiperparámetros de un estimador¶
Los hiperparámetros son parámetros que no se aprenden directamente dentro de los estimadores. En scikit-learn se pasan como argumentos al constructor de las clases de estimadores. Los ejemplos típicos incluyen C, kernel y gamma para el Clasificador de Vectores de Soporte, alpha para Lasso, etc.
Es posible y recomendable buscar en el espacio de hiperparámetros la mejor puntuación de validación cruzada.
Cualquier parámetro proporcionado al construir un estimador puede ser optimizado de esta manera. Específicamente, para encontrar los nombres y valores actuales de todos los parámetros de un estimador determinado, utiliza:
estimator.get_params()
Una búsqueda consiste en:
un estimador (regresor o clasificador como
sklearn.svm.SVC());un espacio de parámetros;
un método de búsqueda o muestreo de candidatos;
un esquema de validación cruzada; y
En scikit-learn se proporcionan dos enfoques genéricos para la búsqueda de parámetros: para valores dados, GridSearchCV considera exhaustivamente todas las combinaciones de parámetros, mientras que RandomizedSearchCV puede muestrear un número determinado de candidatos de un espacio de parámetros con una distribución especificada. Ambas herramientas tienen sus homólogos sucesivos HalvingGridSearchCV y HalvingRandomSearchCV, que pueden ser mucho más rápidos a la hora de encontrar una buena combinación de parámetros.
Después de describir estas herramientas, detallamos las mejores prácticas aplicables a estos enfoques. Algunos modelos permiten estrategias de búsqueda de parámetros especializadas y eficientes, descritas en Alternativas a la búsqueda de parámetros por fuerza bruta.
Ten en cuenta que es habitual que un pequeño subconjunto de esos parámetros pueda tener un gran impacto en el rendimiento predictivo o de cálculo del modelo, mientras que otros pueden dejarse con sus valores por defecto. Se recomienda leer la cadena de documentación de la clase del estimador para obtener una comprensión más fina de su comportamiento esperado, posiblemente leyendo la referencia adjunta a la literatura.
3.2.1. Búsqueda exhaustiva en Cuadrícula¶
La búsqueda en cuadrícula proporcionada por GridSearchCV genera exhaustivamente candidatos a partir de una cuadrícula de valores de parámetros especificados con el parámetro param_grid. Por ejemplo, la siguiente param_grid:
param_grid = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
especifica que se deben explorar dos cuadrículas: una con un kernel lineal y valores de C en [1, 10, 100, 1000], y la segunda con un kernel RBF, y el producto cruzado de valores de C en [1, 10, 100, 1000] y valores de gamma en [0.001, 0.0001].
La instancia GridSearchCV implementa la API de estimadores habitual: al «ajustarla» a un conjunto de datos se evalúan todas las combinaciones posibles de valores de los parámetros y se retiene la mejor combinación.
Ejemplos:
Consulta Estimación de parámetros utilizando la búsqueda en cuadrícula con validación cruzada para ver un ejemplo de cálculo de Búsqueda en Cuadrícula en el conjunto de datos de dígitos.
Consulta Ejemplo de pipeline para la extracción y evaluación de características de texto para ver un ejemplo de cómo Grid Search (búsqueda en cuadrícula) acopla los parámetros de un extractor de características de documentos de texto (vectorizador de recuento de n-gramas y transformador TF-IDF) con un clasificador (en este caso un SVM lineal entrenado con SGD con red elástica o penalización L2) utilizando una instancia
pipeline.Pipeline.Consulta Validación cruzada anidada y no anidada para ver un ejemplo de Grid Search (búsqueda en cuadrícula) dentro de un bucle de validación cruzada en el conjunto de datos iris. Esta es la mejor práctica para evaluar el rendimiento de un modelo con búsqueda en cuadrícula.
Consulta Demostración de la evaluación multimétrica en cross_val_score y GridSearchCV para ver un ejemplo de
GridSearchCVutilizado para evaluar múltiples métricas simultáneamente.Consulta Balancear la complejidad del modelo y la puntuación de validación cruzada para ver un ejemplo de uso de la interfaz
refit=callableenGridSearchCV. El ejemplo muestra cómo esta interfaz añade cierta flexibilidad a la hora de identificar el «mejor» estimador. Esta interfaz también puede utilizarse en la evaluación de múltiples métricas.Consulta Comparación estadística de modelos utilizando la búsqueda en cuadrícula para ver un ejemplo de cómo hacer una comparación estadística de las salidas de
GridSearchCV.
3.2.2. Optimización Aleatoria de Parámetros¶
Aunque el uso de una cuadrícula de ajustes de parámetros es el método más utilizado actualmente para la optimización de parámetros, otros métodos de búsqueda tienen propiedades más favorables. RandomizedSearchCV implementa una búsqueda aleatoria sobre los parámetros, donde cada ajuste se muestrea a partir de una distribución sobre los posibles valores de los parámetros. Esto tiene dos ventajas principales sobre una búsqueda exhaustiva:
Se puede elegir un presupuesto independientemente del número de parámetros y de los valores posibles.
Añadir parámetros que no influyen en el rendimiento no disminuye la eficiencia.
La especificación de cómo se deben muestrear los parámetros se realiza mediante un diccionario, de forma muy similar a la especificación de parámetros para GridSearchCV. Además, se especifica un presupuesto de cálculo, que es el número de candidatos muestreados o iteraciones de muestreo, utilizando el parámetro n_iter. Para cada parámetro, se puede especificar una distribución sobre posibles valores o una lista de opciones discretas (que se muestrearán uniformemente):
{'C': scipy.stats.expon(scale=100), 'gamma': scipy.stats.expon(scale=.1),
'kernel': ['rbf'], 'class_weight':['balanced', None]}
Este ejemplo utiliza el módulo scipy.stats, que contiene muchas distribuciones útiles para el muestreo de parámetros, como expon, gamma, uniform o randint.
En principio, se puede pasar cualquier función que proporcione un método rvs (muestra de variante aleatoria) para muestrear un valor. Una llamada a la función rvs debe proporcionar muestras aleatorias independientes de los posibles valores de los parámetros en llamadas consecutivas.
Advertencia
Las distribuciones en
scipy.statsanteriores a la versión scipy 0.16 no permiten especificar un estado aleatorio. En su lugar, utilizan el estado aleatorio global de numpy, que puede ser sembrado a través denp.random.seedo establecido utilizandonp.random.set_state. Sin embargo, a partir de scikit-learn 0.18, el módulosklearn.model_selectionestablece el estado aleatorio proporcionado por el usuario si scipy >= 0.16 también está disponible.
Para los parámetros continuos, como C arriba, es importante especificar una distribución continua para aprovechar al máximo la aleatorización. De esta manera, el aumento de n_iter siempre conducirá a una búsqueda más fina.
Una variable aleatoria continua log-uniforme está disponible a través de loguniform. Esta es una versión continua de los parámetros log-espaciados. Por ejemplo, para especificar C arriba, se puede usar loguniform(1, 100) en lugar de [1, 10, 100] o np.logspace(0, 2, num=1000). Este es un alias de stats.reciprocal de SciPy.
Reflejando el ejemplo anterior en la búsqueda en cuadrícula, podemos especificar una variable aleatoria continua que se distribuye log-uniformemente entre 1e0 y 1e3:
from sklearn.utils.fixes import loguniform
{'C': loguniform(1e0, 1e3),
'gamma': loguniform(1e-4, 1e-3),
'kernel': ['rbf'],
'class_weight':['balanced', None]}
Ejemplos:
Comparando la búsqueda aleatorizada y la búsqueda en cuadrícula para la estimación de hiperparámetros compara el uso y la eficiencia de la búsqueda aleatoria y la búsqueda en cuadrícula.
Referencias:
Bergstra, J. y Bengio, Y., Random search for hyper-parameter optimization, The Journal of Machine Learning Research (2012)
3.2.3. Búsqueda de los parámetros óptimos con la reducción sucesiva a la mitad¶
Scikit-learn también proporciona los estimadores HalvingGridSearchCV y HalvingRandomSearchCV que se pueden utilizar para buscar un espacio de parámetros utilizando la reducción sucesiva a la mitad 1 2. La reducción sucesiva a la mitad (successive halving, SH) es como un torneo entre combinaciones de parámetros candidatos. SH es un proceso de selección iterativo en el que todos los candidatos (las combinaciones de parámetros) se evalúan con una pequeña cantidad de recursos en la primera iteración. Sólo algunos de estos candidatos se seleccionan para la siguiente iteración, a la que se asignan más recursos. Para el ajuste de parámetros, el recurso suele ser el número de muestras de entrenamiento, pero también puede ser un parámetro numérico arbitrario como n_estimators en un bosque aleatorio.
Como se ilustra en la siguiente figura, sólo un subconjunto de candidatos “sobrevive” hasta la última iteración. Se trata de los candidatos que se han clasificado sistemáticamente entre los candidatos con mayor puntuación en todas las iteraciones. A cada iteración se le asigna una cantidad creciente de recursos por candidato, en este caso el número de muestras.
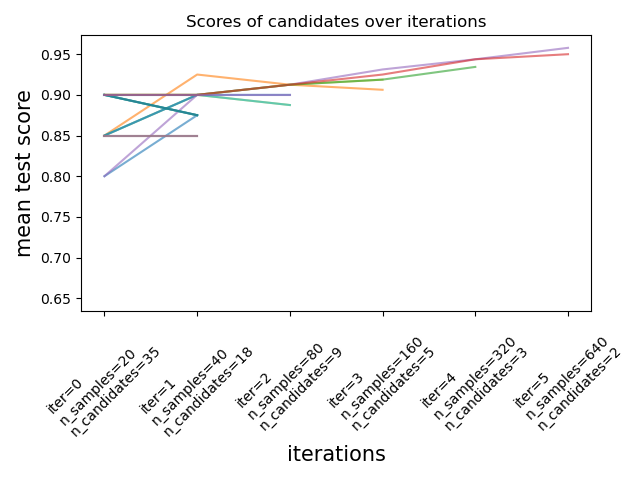
Aquí describimos brevemente los parámetros principales, pero cada parámetro y sus interacciones se describen con más detalle en las siguientes secciones. El parámetro factor (> 1) controla la tasa de crecimiento de los recursos y la tasa de disminución del número de candidatos. En cada iteración, el número de recursos por candidato se multiplica por factor y el número de candidatos se divide por el mismo factor. Junto con resource y min_resources, factor es el parámetro más importante para controlar la búsqueda en nuestra implementación, aunque un valor de 3 suele funcionar bien. factor controla efectivamente el número de iteraciones en HalvingGridSearchCV y el número de candidatos (por defecto) e iteraciones en HalvingRandomSearchCV. También se puede utilizar aggressive_elimination=True si el número de recursos disponibles es pequeño. Hay más control disponible mediante el ajuste del parámetro min_resources.
Estos estimadores son todavía experimentales: sus predicciones y su API podrían cambiar sin ningún ciclo de obsolescencia. Para utilizarlos, es necesario importar explícitamente enable_halving_search_cv:
>>> # explicitly require this experimental feature
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> # now you can import normally from model_selection
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> from sklearn.model_selection import HalvingRandomSearchCV
Ejemplos:
3.2.3.1. Elegir min_resources y el número de candidatos¶
Además de factor, los dos parámetros principales que influyen en el comportamiento de una búsqueda sucesiva a la mitad son el parámetro min_resources y el número de candidatos (o combinaciones de parámetros) que se evalúan. min_resources es la cantidad de recursos asignados en la primera iteración para cada candidato. El número de candidatos se especifica directamente en HalvingRandomSearchCV, y se determina a partir del parámetro param_grid de HalvingGridSearchCV.
Consideremos un caso en el que el recurso es el número de muestras, y en el que tenemos 1000 muestras. En teoría, con min_resources=10 y factor=2, podemos ejecutar como máximo 7 iteraciones con el siguiente número de muestras: [10, 20, 40, 80, 160, 320, 640].
Pero dependiendo del número de candidatos, podríamos realizar menos de 7 iteraciones: si empezamos con un pequeño número de candidatos, la última iteración podría utilizar menos de 640 muestras, lo que significa no utilizar todos los recursos disponibles (muestras). Por ejemplo, si empezamos con 5 candidatos, sólo necesitaremos 2 iteraciones: 5 candidatos para la primera iteración, y luego 5 // 2 = 2 candidatos en la segunda iteración, después de la que sabremos cuál es el mejor candidato (por lo que no necesitamos una tercera). Sólo estaríamos utilizando como máximo 20 muestras, lo cual es un desperdicio ya que tenemos 1000 muestras a nuestra disposición. Por otro lado, si empezamos con un número elevado de candidatos, podríamos acabar con muchos candidatos en la última iteración, lo que no siempre es ideal: significa que muchos candidatos correrán con todos los recursos, reduciendo básicamente el procedimiento a una búsqueda estándar.
En el caso de HalvingRandomSearchCV, el número de candidatos se establece por defecto de forma que la última iteración utilice la mayor cantidad posible de recursos disponibles. Para HalvingGridSearchCV, el número de candidatos viene determinado por el parámetro param_grid. Cambiar el valor de min_resources afectará al número de iteraciones posibles, y como resultado también tendrá un efecto en el número ideal de candidatos.
Otra consideración a la hora de elegir min_resources es si es fácil o no discriminar entre candidatos buenos y malos con una pequeña cantidad de recursos. Por ejemplo, si necesitas muchas muestras para distinguir entre parámetros buenos y malos, se recomienda un min_resources alto. Por otro lado, si la distinción es clara incluso con una pequeña cantidad de muestras, entonces puede ser preferible un min_resources pequeño, ya que aceleraría el cálculo.
Observa en el ejemplo anterior que la última iteración no utiliza el máximo de recursos disponibles: Hay 1000 muestras disponibles, pero sólo se utilizan 640, como máximo. Por defecto, tanto HalvingRandomSearchCV como HalvingGridSearchCV intentan utilizar la mayor cantidad de recursos posible en la última iteración, con la restricción de que esta cantidad de recursos debe ser un múltiplo tanto de min_resources como de factor (esta restricción quedará clara en la siguiente sección). HalvingRandomSearchCV logra esto mediante el muestreo de la cantidad correcta de candidatos, mientras que HalvingGridSearchCV lo logra estableciendo adecuadamente min_resources. Por favor, consulta Agotar los recursos disponibles para más detalles.
3.2.3.2. Cantidad de recursos y número de candidatos en cada iteración¶
En cualquier iteración i, a cada candidato se le asigna una cantidad determinada de recursos que denotamos n_resources_i. Esta cantidad está controlada por los parámetros factor y min_resources como sigue (factor es estrictamente mayor que 1):
n_resources_i = factor**i * min_resources,
o, de forma equivalente:
n_resources_{i+1} = n_resources_i * factor
donde min_resources == n_resources_0 es la cantidad de recursos utilizados en la primera iteración. factor también define las proporciones de candidatos que se seleccionarán para la siguiente iteración:
n_candidates_i = n_candidates // (factor ** i)
o, de forma equivalente:
n_candidates_0 = n_candidates
n_candidates_{i+1} = n_candidates_i // factor
Así que en la primera iteración, utilizamos min_resources recursos n_candidates veces. En la segunda iteración, utilizamos min_resources * factor recursos n_candidates // factor veces. La tercera vuelve a multiplicar los recursos por candidato y divide el número de candidatos. Este proceso se detiene cuando se alcanza la cantidad máxima de recursos por candidato, o cuando hemos identificado al mejor candidato. El mejor candidato se identifica en la iteración que está evaluando factor o menos candidatos (ver justo debajo para una explicación).
Aquí hay un ejemplo con min_resources=3 y factor=2, empezando con 70 candidatos:
|
|
|---|---|
3 (=min_resources) |
70 (=n_candidates) |
3 * 2 = 6 |
70 // 2 = 35 |
6 * 2 = 12 |
35 // 2 = 17 |
12 * 2 = 24 |
17 // 2 = 8 |
24 * 2 = 48 |
8 // 2 = 4 |
48 * 2 = 96 |
4 // 2 = 2 |
Podemos notar que:
el proceso se detiene en la primera iteración que evalúa
factor=2candidatos: el mejor candidato es el mejor de estos 2 candidatos. No es necesario ejecutar una iteración adicional, ya que sólo evaluaría un candidato (el mejor, que ya hemos identificado). Por esta razón, en general, queremos que la última iteración ejecute como máximofactorcandidatos. Si la última iteración evalúa más defactorcandidatos, entonces esta última iteración se reduce a una búsqueda regular (como enRandomizedSearchCVoGridSearchCV).cada
n_resources_ies un múltiplo tanto defactorcomo demin_resources(lo cual se confirma por su definición anterior).
La cantidad de recursos que se utilizan en cada iteración se puede encontrar en el atributo n_resources_.
3.2.3.3. Elegir un recurso¶
Por defecto, el recurso se define en términos del número de muestras. Es decir, cada iteración utilizará una cantidad creciente de muestras para entrenar. Sin embargo, puedes especificar manualmente un parámetro para utilizarlo como recurso con el parámetro resource. Aquí hay un ejemplo donde el recurso se define en términos del número de estimadores de un bosque aleatorio:
>>> from sklearn.datasets import make_classification
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>>
>>> param_grid = {'max_depth': [3, 5, 10],
... 'min_samples_split': [2, 5, 10]}
>>> base_estimator = RandomForestClassifier(random_state=0)
>>> X, y = make_classification(n_samples=1000, random_state=0)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, resource='n_estimators',
... max_resources=30).fit(X, y)
>>> sh.best_estimator_
RandomForestClassifier(max_depth=5, n_estimators=24, random_state=0)
Ten en cuenta que no es posible presupuestar en un parámetro que es parte de la cuadrícula del parámetro.
3.2.3.4. Agotar los recursos disponibles¶
Como se ha mencionado anteriormente, el número de recursos que se utiliza en cada iteración depende del parámetro min_resources. Si tienes muchos recursos disponibles pero empiezas con un número bajo de recursos, algunos de ellos podrían ser desperdiciados (es decir, no utilizados):
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid= {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources=20).fit(X, y)
>>> sh.n_resources_
[20, 40, 80]
El proceso de búsqueda sólo utilizará 80 recursos como máximo, mientras que nuestra cantidad máxima de recursos disponibles es n_samples=1000. Aquí, tenemos min_resources = r_0 = 20.
Para HalvingGridSearchCV, por defecto, el parámetro min_resources se establece en “exhaust”. Esto significa que min_resources se establece automáticamente de forma que la última iteración pueda utilizar tantos recursos como sea posible, dentro del límite de max_resources:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources='exhaust').fit(X, y)
>>> sh.n_resources_
[250, 500, 1000]
min_resources se estableció aquí automáticamente en 250, lo que hace que la última iteración utilice todos los recursos. El valor exacto que se utiliza depende del número de parámetros candidatos, en max_resources y en factor.
Para HalvingRandomSearchCV, el agotamiento de los recursos puede hacerse de dos maneras:
estableciendo
min_resources='exhaust', al igual que paraHalvingGridSearchCV;estableciendo
n_candidates='exhaust'.
Ambas opciones son mutuamente excluyentes: usar min_resources='exhaust' requiere conocer el número de candidatos, y simétricamente n_candidates='exhaust' requiere conocer min_resources.
En general, agotar el número total de recursos conduce a un mejor parámetro candidato final, y requiere ligeramente más tiempo.
3.2.3.5. Eliminación agresiva de candidatos¶
Idealmente, queremos que la última iteración evalúe factor candidatos (ver Cantidad de recursos y número de candidatos en cada iteración). Luego sólo tenemos que elegir el mejor. Cuando el número de recursos disponibles es pequeño respecto al número de candidatos, es posible que la última iteración tenga que evaluar más de factor candidatos:
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>>
>>>
>>> param_grid = {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, max_resources=40,
... aggressive_elimination=False).fit(X, y)
>>> sh.n_resources_
[20, 40]
>>> sh.n_candidates_
[6, 3]
Como no podemos utilizar más de max_resources=40 recursos, el proceso tiene que detenerse en la segunda iteración que evalúa más de factor=2 candidatos.
Usando el parámetro aggressive_elimination, puedes forzar el proceso de búsqueda para que termine con menos de factor candidatos en la última iteración. Para ello, el proceso eliminará tantos candidatos como sea necesario utilizando min_resources recursos:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2,
... max_resources=40,
... aggressive_elimination=True,
... ).fit(X, y)
>>> sh.n_resources_
[20, 20, 40]
>>> sh.n_candidates_
[6, 3, 2]
Observa que terminamos con 2 candidatos en la última iteración ya que hemos eliminado suficientes candidatos durante las primeras iteraciones, utilizando n_resources = min_resources = 20.
3.2.3.6. Analizar resultados con el atributo cv_results_¶
El atributo cv_results_ contiene información útil para analizar los resultados de una búsqueda. Se puede convertir en un dataframe de pandas con df = pd.DataFrame(est.cv_results_). El atributo cv_results_ de HalvingGridSearchCV y HalvingRandomSearchCV es similar al de GridSearchCV y RandomizedSearchCV, con información adicional relacionada con el proceso de reducción sucesiva a la mitad.
A continuación se muestra un ejemplo con algunas de las columnas de un dataframe (truncado):
iter |
n_resources |
mean_test_score |
params |
|
|---|---|---|---|---|
0 |
0 |
125 |
0.983667 |
{“criterion”: “entropy”, “max_depth”: None, “max_features”: 9, “min_samples_split”: 5} |
1 |
0 |
125 |
0.983667 |
{“criterion”: “gini”, “max_depth”: None, “max_features”: 8, “min_samples_split”: 7} |
2 |
0 |
125 |
0.983667 |
{“criterion”: “gini”, “max_depth”: None, “max_features”: 10, “min_samples_split”: 10} |
3 |
0 |
125 |
0.983667 |
{“criterion”: “entropy”, “max_depth”: None, “max_features”: 6, “min_samples_split”: 6} |
… |
… |
… |
… |
… |
15 |
2 |
500 |
0.951958 |
{“criterion”: “entropy”, “max_depth”: None, “max_features”: 9, “min_samples_split”: 10} |
16 |
2 |
500 |
0.947958 |
{“criterion”: “gini”, “max_depth”: None, “max_features”: 10, “min_samples_split”: 10} |
17 |
2 |
500 |
0.951958 |
{“criterion”: “gini”, “max_depth”: None, “max_features”: 10, “min_samples_split”: 4} |
18 |
3 |
1000 |
0.961009 |
{“criterion”: “entropy”, “max_depth”: None, “max_features”: 9, “min_samples_split”: 10} |
19 |
3 |
1000 |
0.955989 |
{“criterion”: “gini”, “max_depth”: None, “max_features”: 10, “min_samples_split”: 4} |
Cada fila corresponde a una combinación de parámetros dada (un candidato) y a una iteración determinada. La iteración viene dada por la columna iter. La columna n_resources indica el número de recursos utilizados.
En el ejemplo anterior, la mejor combinación de parámetros es {'criterion': 'entropy', 'max_depth': None, 'max_features': 9, 'min_samples_split': 10} ya que ha alcanzado la última iteración (3) con la mayor puntuación: 0.96.
Referencias:
- 1
K. Jamieson, A. Talwalkar, Non-stochastic Best Arm Identification and Hyperparameter Optimization, in proc. of Machine Learning Research, 2016.
- 2
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, A. Talwalkar, Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization, in Machine Learning Research 18, 2018.
3.2.4. Tips para la búsqueda de parámetros¶
3.2.4.1. Especificar una métrica objetiva¶
Por defecto, la búsqueda de parámetros utiliza la función score del estimador para evaluar una configuración de parámetros. Estas son sklearn.metrics.accuracy_score para la clasificación y sklearn.metrics.r2_score para la regresión. Para algunas aplicaciones, otras funciones de puntuación son más adecuadas (por ejemplo, en la clasificación no balanceada, la puntuación de exactitud es a menudo poco informativa). Se puede especificar una función de puntuación alternativa a través del parámetro scoring de la mayoría de las herramientas de búsqueda de parámetros. Ver El parámetro scoring: definir las reglas de evaluación del modelo para más detalles.
3.2.4.2. Especificar múltiples métricas para la evaluación¶
GridSearchCV y RandomizedSearchCV permiten especificar múltiples métricas para el parámetro scoring.
La puntuación multimétrica puede especificarse como una lista de cadenas de nombres de puntuaciones predefinidos o como un dict que mapea el nombre del puntuador a la función de puntuación y/o el nombre o los nombres predefinidos del puntuador. Ver Utilizando evaluación métrica múltiple para más detalles.
Cuando se especifican múltiples métricas, el parámetro refit debe establecerse en la métrica (cadena) para la cual se encontrará best_params_ y se utilizará para construir el best_estimator_ en todo el conjunto de datos. Si la búsqueda no debe ser reajustada, establece refit=False. Si se deja refit con el valor por defecto None se producirá un error cuando se utilicen múltiples métricas.
Ver Demostración de la evaluación multimétrica en cross_val_score y GridSearchCV para un ejemplo de uso.
HalvingRandomSearchCV y HalvingGridSearchCV no soportan la puntuación multimétrica.
3.2.4.3. Estimadores compuestos y espacios de parámetros¶
GridSearchCV y RandomizedSearchCV permiten buscar sobre parámetros de estimadores compuestos o anidados como Pipeline, ColumnTransformer, VotingClassifier o CalibratedClassifierCV utilizando una sintaxis dedicada <estimator>__<parameter>:
>>> from sklearn.model_selection import GridSearchCV
>>> from sklearn.calibration import CalibratedClassifierCV
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_moons
>>> X, y = make_moons()
>>> calibrated_forest = CalibratedClassifierCV(
... base_estimator=RandomForestClassifier(n_estimators=10))
>>> param_grid = {
... 'base_estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(calibrated_forest, param_grid, cv=5)
>>> search.fit(X, y)
GridSearchCV(cv=5,
estimator=CalibratedClassifierCV(...),
param_grid={'base_estimator__max_depth': [2, 4, 6, 8]})
Aquí, <estimator>` es el nombre del parámetro del estimador anidado, en este caso ``base_estimator. Si el metaestimador se construye como una colección de estimadores como en pipeline.Pipeline, entonces <estimator> se refiere al nombre del estimador, ver Parámetros anidados. En la práctica, puede haber varios niveles de anidación:
>>> from sklearn.pipeline import Pipeline
>>> from sklearn.feature_selection import SelectKBest
>>> pipe = Pipeline([
... ('select', SelectKBest()),
... ('model', calibrated_forest)])
>>> param_grid = {
... 'select__k': [1, 2],
... 'model__base_estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(pipe, param_grid, cv=5).fit(X, y)
Consulta Pipeline: estimadores encadenados para realizar búsquedas de parámetros sobre pipelines.
3.2.4.4. Selección de modelos: desarrollo y evaluación¶
La selección del modelo mediante la evaluación de varios ajustes de los parámetros puede verse como una forma de utilizar los datos etiquetados para «entrenar» los parámetros de la cuadrícula.
A la hora de evaluar el modelo resultante, es importante hacerlo sobre las muestras retenidas que no se han visto durante el proceso de búsqueda en cuadrícula: se recomienda dividir los datos en un conjunto de desarrollo (para alimentar la instancia GridSearchCV) y un conjunto de evaluación para calcular las métricas de rendimiento.
Esto puede hacerse utilizando la función de utilidad train_test_split.
3.2.4.5. Paralelismo¶
Las herramientas de búsqueda de parámetros evalúan cada combinación de parámetros en cada pliegue de datos de forma independiente. Los cálculos pueden ejecutarse en paralelo utilizando la palabra clave n_jobs=-1. Consulta la definición de la función para más detalles, y también la entrada del Glosario para n_jobs.
3.2.4.6. Robustez frente a los fallos¶
Algunos ajustes de los parámetros pueden provocar un fallo en fit de uno o más pliegues de los datos. Por defecto, esto hará que toda la búsqueda falle, incluso si algunos ajustes de los parámetros pueden ser evaluados completamente. Si se establece error_score=0 (o =np.NaN), el procedimiento será más robusto ante este tipo de fallos, emitiendo una advertencia y estableciendo la puntuación para ese pliegue en 0 (o NaN), pero completando la búsqueda.
3.2.5. Alternativas a la búsqueda de parámetros por fuerza bruta¶
3.2.5.1. Validación cruzada específica del modelo¶
Algunos modelos pueden ajustarse a los datos para un rango de valores de algún parámetro casi con la misma eficacia que el ajuste del estimador para un único valor del parámetro. Esta característica puede aprovecharse para realizar una validación cruzada más eficiente utilizada para la selección del modelo de este parámetro.
El parámetro más común que se presta a esta estrategia es el que codifica la fuerza del regularizador. En este caso decimos que calculamos el camino de regularización del estimador.
Esta es la lista de estos modelos:
Modelo de Red Elástica con ajuste iterativo a lo largo de una trayectoria de regularización. |
|
Modelo de Regresión de Ángulo Mínimo con Validación Cruzada. |
|
Modelo lineal Lasso con ajuste iterativo a lo largo del camino de regularización. |
|
Validación cruzada Lasso, utilizando el algoritmo LARS. |
|
Clasificador de Regresión Logística CV (también conocido como logit, MaxEnt). |
|
ElasticNet multitarea L1/L2 con validación cruzada incorporada. |
|
Modelo Lasso multitarea entrenado con la norma mixta L1/L2 como regularizador. |
|
Modelo de búsqueda de correspondencias ortogonales (Orthogonal Matching Pursuit, OMP) con validación cruzada. |
|
Regresión de cresta con validación cruzada incorporada. |
|
Clasificador de cresta con validación cruzada incorporada. |
3.2.5.2. Criterio de Información¶
Algunos modelos pueden ofrecer una fórmula de forma cerrada teórica de la información de la estimación óptima del parámetro de regularización mediante el cálculo de un solo camino de regularización (en lugar de varios cuando se utiliza la validación cruzada).
Esta es la lista de modelos que se benefician del Criterio de Información de Akaike (Akaike Information Criterion, AIC) o del Criterio de Información Bayesiano (Criterio de Información Bayesiano, BIC) para la selección automática de modelos:
Ajuste del modelo Lasso con Lars utilizando BIC o AIC para la selección del modelo |
3.2.5.3. Estimaciones Fuera de la Bolsa (Out of Bag)¶
Cuando se utilizan métodos de ensemble basados en el empaquetado (bagging), es decir, la generación de nuevos conjuntos de entrenamiento mediante muestreo con reemplazo, parte del conjunto de entrenamiento queda sin utilizar. Para cada clasificador de ensemble, se omite una parte diferente del conjunto de entrenamiento.
Esta porción omitida puede utilizarse para estimar el error de generalización sin tener que depender de un conjunto de validación separado. Esta estimación es «gratuita», ya que no se necesitan datos adicionales y puede utilizarse para la selección del modelo.
Esto está actualmente implementado en las siguientes clases:
Un clasificador de bosque aleatorio. |
|
Un regresor de bosque aleatorio. |
|
Un clasificador de árboles extra (extra-trees). |
|
Un regresor de árboles extra (extra-trees). |
|
Potenciación del gradiente para clasificación. |
|
Potenciación del Gradiente para regresión. |