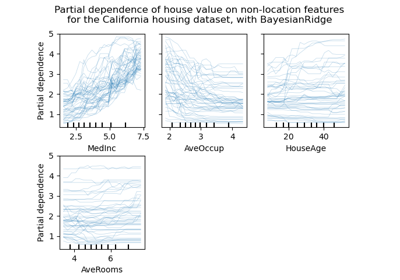
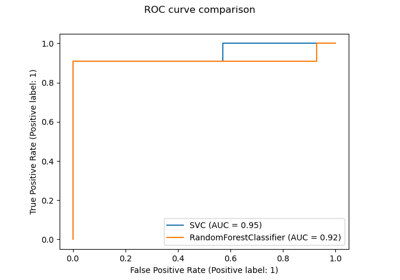
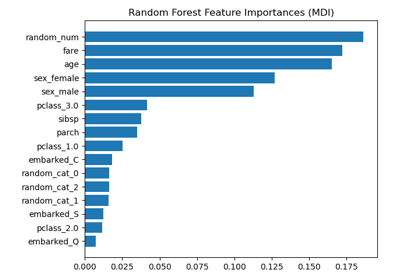
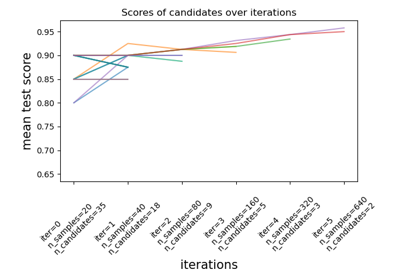
sklearn.ensemble.RandomForestClassifier¶
- class sklearn.ensemble.RandomForestClassifier¶
Un clasificador de bosque aleatorio.
Un bosque aleatorio es un metaestimador que ajusta un número de clasificadores de árboles de decisión en varias submuestras del conjunto de datos y utiliza el promedio para mejorar la precisión predictiva y controlar el sobreajuste. El tamaño de la submuestra se controla con el parámetro
max_samplessibootstrap=True(predeterminado), de lo contrario se utiliza todo el conjunto de datos para construir cada árbol.Leer más en el Manual de Usuario.
- Parámetros
- n_estimatorsint, default=100
El número de árboles en el bosque.
Distinto en la versión 0.22: El valor predeterminado de
n_estimatorscambió de 10 a 100 en 0.22.- criterion{«gini», «entropy»}, default=»gini»
La función para medir la calidad de una división. Los criterios admitidos son «gini» para la impureza de Gini y «entropy» para la ganancia de información. Nota: este parámetro es específico del árbol.
- max_depthint, default=None
La profundidad máxima del árbol. Si es None, los nodos se expanden hasta que todas las hojas sean puras o hasta que todas las hojas contengan menos que min_samples_split muestras.
- min_samples_splitint o float, default=2
El número mínimo de muestras necesarias para dividir un nodo interno:
Si es int, entonces considera
min_samples_splitcomo el número mínimo.Si es float, entonces
min_samples_splites una fracción yceil(min_samples_split * n_samples)son el número mínimo de muestras para cada división.
Distinto en la versión 0.18: Se añadieron valores de punto flotante (float) para las fracciones.
- min_samples_leafint o float, default=1
El número mínimo de muestras requerido para estar en un nodo hoja. Un punto de división a cualquier profundidad sólo se considerará si deja al menos
min_samples_leafmuestras de entrenamiento en cada una de las ramas izquierda y derecha. Esto puede tener el efecto de suavizar el modelo, especialmente en la regresión.Si es int, entonces considera
min_samples_leafcomo el número mínimo.Si es float, entonces
min_samples_leafes una fracción yceil(min_samples_leaf * n_samples)son el número mínimo de muestras para cada nodo.
Distinto en la versión 0.18: Se añadieron valores de punto flotante (float) para las fracciones.
- min_weight_fraction_leaffloat, default=0.0
La fracción ponderada mínima de la suma total de ponderaciones (de todas las muestras de entrada) requeridas para estar en un nodo hoja. Las muestras tienen la misma ponderación cuando no se proporciona sample_weight.
- max_features{«auto», «sqrt», «log2»}, int o float, default=»auto»
El número de características a considerar a la hora de buscar la mejor división:
Si es int, entonces considera
max_featurescaracterísticas en cada división.Si es float, entonces
max_featureses una fracción yround(max_features * n_features)características se consideran en cada división.Si es «auto», entonces
max_features=sqrt(n_features).Si es «sqrt», entonces
max_features=sqrt(n_features)(igual que «auto»).Si es «log2», entonces
max_features=log2(n_features).Si es None, entonces
max_features=n_features.
Nota: la búsqueda de una división no se detiene hasta que se encuentre al menos una partición válida de las muestras de nodos, incluso si requiere inspeccionar efectivamente más de
max_featurescaracterísticas.- max_leaf_nodesint, default=None
Hace crecer árboles con
max_leaf_nodesen forma best-first. Los mejores nodos se definen como una reducción relativa de la impureza. Si es None, entonces el número de nodos hoja es ilimitado.- min_impurity_decreasefloat, default=0.0
Un nodo se dividirá si esta división induce una disminución de la impureza mayor o igual a este valor.
La ecuación de disminución de impurezas ponderada es la siguiente:
N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity)
donde
Nes el número total de muestras,N_tes el número de muestras en el nodo actual,N_t_Les el número de muestras en el hijo izquierdo, yN_t_Res el número de muestras en el hijo derecho.N,N_t,N_t_RyN_t_Lse refieren a la suma ponderada, si se pasasample_weight.Nuevo en la versión 0.19.
- min_impurity_splitfloat, default=None
Umbral para la parada anticipada en el crecimiento del árbol. Un nodo se dividirá si su impureza está por encima del umbral, de lo contrario es una hoja.
Obsoleto desde la versión 0.19:
min_impurity_splitha quedado obsoleto en favor demin_impurity_decreaseen 0.19. El valor predeterminado demin_impurity_splitha cambiado de 1e-7 a 0 en 0.23 y se eliminará en 1.0 (renombrado de 0.25). Utilizamin_impurity_decreaseen su lugar.- bootstrapbool, default=True
Si se utilizan muestras bootstrap al construir los árboles. Si es False, se utiliza todo el conjunto de datos para construir cada árbol.
- oob_scorebool, default=False
Si se utilizan muestras out-of-bag para estimar la precisión de la generalización.
- n_jobsint, default=None
El número de trabajos a ejecutar en paralelo.
fit,predict,decision_pathyapplyson todos paralelizados sobre los árboles.Nonesignifica 1 a menos que esté en un contextojoblib.parallel_backend.-1significa que se utilizan todos los procesadores. Ver Glosario para más detalles.- random_stateentero, instancia de RandomState o None, default=None
Controla tanto la aleatoriedad del bootstrapping de las muestras utilizadas al construir los árboles (si
bootstrap=True) como el muestreo de las características a considerar al buscar la mejor división en cada nodo (simax_features < n_features). Ver Glosario para obtener detalles.- verboseint, default=0
Controla la verbosidad al ajustar y predecir.
- warm_startbool, default=False
Cuando se establece como
True, reutiliza la solución de la llamada previa para ajustar y añadir más estimadores al ensemble, de lo contrario, sólo se ajusta un bosque nuevo. Ver Glosario.- class_weight{«balanced», «balanced_subsample»}, dict o list de dicts, default=None
Ponderaciones asociadas a las clases de la forma
{class_label: weight}. Si no se da, se supone que todas las clases tienen ponderación uno. Para los problemas de salida múltiple, se puede proporcionar una lista de dicts en el mismo orden que las columnas de y.Ten en cuenta que para la salida múltiple (incluyendo la multietiqueta) las ponderaciones deben ser definidas para cada clase de cada columna en su propio diccionario. Por ejemplo, para la clasificación multietiqueta de cuatro clases las ponderaciones deben ser [{0: 1, 1: 1}, {0: 1, 1: 5}, {0: 1, 1: 1}, {0: 1, 1: 1}] en lugar de [{1:1}, {2:5}, {3:1}, {4:1}].
El modo «balanced» utiliza los valores de y para ajustar automáticamente las ponderaciones de forma inversamente proporcional a las frecuencias de las clases en los datos de entrada como
n_samples / (n_classes * np.bincount(y))El modo «balanced_subsample» es el mismo que «balanced», excepto que las ponderaciones se calculan en base a la muestra bootstrap para cada árbol que crece.
Para la salida múltiple, las ponderaciones de cada columna de y se multiplicarán.
Ten en cuenta que estas ponderaciones se multiplicarán con sample_weight (pasado por el método de ajuste) si se especifica sample_weight.
- ccp_alphaflotante no negativo, default=0.0
Parámetro de complejidad utilizado para la Poda de Costo-Complejidad Mínimo. Se elegirá el subárbol con el mayor costo-complejidad que sea menor que
ccp_alpha. Por defecto, no se realiza ninguna poda. Ver Poda de Coste-Complejidad Mínima para obtener detalles.Nuevo en la versión 0.22.
- max_samplesint o float, default=None
Si bootstrap es True, el número de muestras a extraer de X para entrenar cada estimador base.
Si es None (predeterminado), entonces extrae
X.shape[0]muestras.Si es int, entonces extrae
max_samplesmuestras.Si es float, entonces extrae
max_samples * X.shape[0]muestras. Por lo tanto,max_samplesdebería estar en el intervalo(0, 1).
Nuevo en la versión 0.22.
- Atributos
- base_estimator_DecisionTreeClassifier
La plantilla del estimador hijo utilizada para crear la colección de subestimadores ajustados.
- estimators_list de DecisionTreeClassifier
La colección de subestimadores ajustados.
- classes_ndarray de forma (n_classes,) o una list de dichos arreglos
Las etiquetas de clases (problema de salida única), o una lista de arreglos de etiquetas de clases (problema de salida múltiple).
- n_classes_int o list
El número de clases (problema de salida única), o una lista que contiene el número de clases para cada salida (problema de salida múltiple).
- n_features_int
El número de características cuando
fites realizado.- n_outputs_int
El número de salidas cuando se realiza el
fit.feature_importances_ndarray de forma (n_features,)Las importancias de las características basadas en las impurezas.
- oob_score_float
Puntuación del conjunto de datos de entrenamiento obtenida mediante una estimación out-of-bag. Este atributo sólo existe cuando
oob_scorees True.- oob_decision_function_ndarray de forma (n_samples, n_classes)
Función de decisión calculada con la estimación out-of-bag en el conjunto de entrenamiento. Si n_estimators es pequeño, es posible que un punto de datos nunca se haya dejado fuera durante el bootstrap. En este caso,
oob_decision_function_podría contener NaN. Este atributo sólo existe cuandooob_scorees True.
Ver también
DecisionTreeClassifier,ExtraTreesClassifier
Notas
Los valores predeterminados de los parámetros que controlan el tamaño de los árboles (por ejemplo,
`max_depth,min_samples_leaf, etc.) conducen a árboles completamente desarrollados y sin podar que pueden ser potencialmente muy grandes en algunos conjuntos de datos. Para reducir el consumo de memoria, la complejidad y el tamaño de los árboles deben controlarse estableciendo los valores de esos parámetros.Las características siempre se permutan aleatoriamente en cada división. Por lo tanto, la mejor división encontrada puede variar, incluso con los mismos datos de entrenamiento,
max_features=n_featuresybootstrap=False, si la mejora del criterio es idéntica para varias divisiones enumeradas durante la búsqueda de la mejor división. Para obtener un comportamiento determinista durante el ajuste, hay que fijarrandom_state.Referencias
- 1
Breiman, «Random Forests», Machine Learning, 45(1), 5-32, 2001.
Ejemplos
>>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.datasets import make_classification >>> X, y = make_classification(n_samples=1000, n_features=4, ... n_informative=2, n_redundant=0, ... random_state=0, shuffle=False) >>> clf = RandomForestClassifier(max_depth=2, random_state=0) >>> clf.fit(X, y) RandomForestClassifier(...) >>> print(clf.predict([[0, 0, 0, 0]])) [1]
Métodos
Aplica los árboles del bosque a X, devuelve los índices de las hojas.
Devuelve la trayectoria de decisión en el bosque.
Construye un bosque de árboles a partir del conjunto de entrenamiento (X, y).
Obtiene los parámetros para este estimador.
Predice la clase para X.
Predice las probabilidades logarítmicas de clase para X.
Predice las probabilidades de clase para X.
Devuelve la precisión media en los datos de prueba y las etiquetas dadas.
Establece los parámetros de este estimador.
- apply()¶
Aplica los árboles del bosque a X, devuelve los índices de las hojas.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Las muestras de entrada. Internamente, se convertirá a
dtype=np.float32. Si se proporciona una matriz dispersa, se convertirá a unacsr_matrixdispersa.
- Devuelve
- X_leavesndarray de forma (n_samples, n_estimators)
Para cada punto de datos x en X y para cada árbol del bosque, devuelve el índice de la hoja en la que termina x.
- decision_path()¶
Devuelve la trayectoria de decisión en el bosque.
Nuevo en la versión 0.18.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Las muestras de entrada. Internamente, se convertirá a
dtype=np.float32. Si se proporciona una matriz dispersa, se convertirá a unacsr_matrixdispersa.
- Devuelve
- indicatormatriz dispersa de forma (n_samples, n_nodes)
Devuelve una matriz de indicadores de nodos donde los elementos distintos de cero indican que las muestras pasan por los nodos. La matriz tiene el formato CSR.
- n_nodes_ptrndarray de forma (n_estimators + 1,)
Las columnas del indicador[n_nodes_ptr[i]:n_nodes_ptr[i+1]] dan el valor del indicador para el i-ésimo estimador.
- property feature_importances_¶
Las importancias de las características basadas en las impurezas.
Cuanto más alta sea, más importante será la característica. La importancia de una característica se calcula como la reducción total (normalizada) del criterio que aporta esa característica. También se conoce como importancia de Gini.
Advertencia: las importancias de características basadas en la impureza pueden ser no representativas para características de alta cardinalidad (muchos valores únicos). Ver
sklearn.inspection.permutation_importancecomo una alternativa.- Devuelve
- feature_importances_ndarray de forma (n_features,)
Los valores de este arreglo suman 1, a menos que todos los árboles sean árboles de un solo nodo que consistan sólo en el nodo raíz, en cuyo caso será un arreglo de ceros.
- fit()¶
Construye un bosque de árboles a partir del conjunto de entrenamiento (X, y).
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Las muestras de entrada de entrenamiento. Internamente, su dtype se convertirá a
dtype=np.float32. Si se proporciona una matriz dispersa, se convertirá a unacsc_matrixdispersa.- yarray-like de forma (n_samples,) o (n_samples, n_outputs)
Los valores objetivo (etiquetas de clase en clasificación, números reales en regresión).
- sample_weightarray-like de forma (n_samples,), default=None
Ponderación de las muestras. Si es None, las muestras se ponderan por igual. Las divisiones que crearían nodos hijos con peso neto cero o negativo se ignoran al buscar una división en cada nodo. En el caso de la clasificación, las divisiones también se ignoran si dan lugar a que una sola clase tenga un peso negativo en cualquiera de los nodos hijos.
- Devuelve
- selfobject
- get_params()¶
Obtiene los parámetros para este estimador.
- Parámetros
- deepbool, default=True
Si es True, devolverá los parámetros para este estimador y los subobjetos contenidos que son estimadores.
- Devuelve
- paramsdict
Nombres de parámetros mapeados a sus valores.
- predict()¶
Predice la clase para X.
La clase predicha de una muestra de entrada es un voto de los árboles del bosque, ponderado por sus estimaciones de probabilidad. Es decir, la clase predicha es la que tiene la estimación de probabilidad media más alta entre los árboles.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Las muestras de entrada. Internamente, se convertirá a
dtype=np.float32. Si se proporciona una matriz dispersa, se convertirá a unacsr_matrixdispersa.
- Devuelve
- yndarray de forma (n_samples,) o (n_samples, n_outputs)
Las clases predichas.
- predict_log_proba()¶
Predice las probabilidades logarítmicas de clase para X.
Las probabilidades logarítmicas de clase predichas de una muestra de entrada se calculan como el logaritmo de las probabilidades medias de clase predichas de los árboles del bosque.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Las muestras de entrada. Internamente, se convertirá a
dtype=np.float32. Si se proporciona una matriz dispersa, se convertirá a unacsr_matrixdispersa.
- Devuelve
- pndarray de forma (n_samples, n_classes), o una list de n_outputs
tales arreglos si n_outputs > 1. Las probabilidades de clase de las muestras de entrada. El orden de las clases corresponde al del atributo classes_.
- predict_proba()¶
Predice las probabilidades de clase para X.
Las probabilidades de clase predichas de una muestra de entrada se calculan como la media de las probabilidades de clase predichas de los árboles del bosque. La probabilidad de clase de un solo árbol es la fracción de muestras de la misma clase en una hoja.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Las muestras de entrada. Internamente, se convertirá a
dtype=np.float32. Si se proporciona una matriz dispersa, se convertirá a unacsr_matrixdispersa.
- Devuelve
- pndarray de forma (n_samples, n_classes), o una list de n_outputs
tales arreglos si n_outputs > 1. Las probabilidades de clase de las muestras de entrada. El orden de las clases corresponde al del atributo classes_.
- score()¶
Devuelve la precisión media en los datos de prueba y las etiquetas dadas.
En la clasificación multietiqueta, se trata de la precisión del subconjunto, que es una métrica rigurosa, ya que se requiere para cada muestra que cada conjunto de etiquetas sea predicho correctamente.
- Parámetros
- Xarray-like de forma (n_samples, n_features)
Muestras de prueba.
- yarray-like de forma (n_samples,) o (n_samples, n_outputs)
Etiquetas verdaderas para
X.- sample_weightarray-like de forma (n_samples,), default=None
Ponderaciones de muestras.
- Devuelve
- scorefloat
Precisión media de
self.predict(X)con respecto ay.
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto en estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma<component>__<parameter>para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia del estimador
Instancia del estimador.