Nota
Haz clic aquí para descargar el código completo del ejemplo o para ejecutar este ejemplo en tu navegador a través de Binder
Iteraciones sucesivas a la mitad¶
Este ejemplo ilustra cómo una búsqueda sucesiva a la mitad (HalvingGridSearchCV y HalvingRandomSearchCV) elige iterativamente la mejor combinación de parámetros entre múltiples candidatos.
import pandas as pd
from sklearn import datasets
import matplotlib.pyplot as plt
from scipy.stats import randint
import numpy as np
from sklearn.experimental import enable_halving_search_cv # noqa
from sklearn.model_selection import HalvingRandomSearchCV
from sklearn.ensemble import RandomForestClassifier
print(__doc__)
Primero definimos el espacio de parámetros y entrenamos una instancia HalvingRandomSearchCV.
rng = np.random.RandomState(0)
X, y = datasets.make_classification(n_samples=700, random_state=rng)
clf = RandomForestClassifier(n_estimators=20, random_state=rng)
param_dist = {"max_depth": [3, None],
"max_features": randint(1, 11),
"min_samples_split": randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"]}
rsh = HalvingRandomSearchCV(
estimator=clf,
param_distributions=param_dist,
factor=2,
random_state=rng)
rsh.fit(X, y)
Out:
HalvingRandomSearchCV(estimator=RandomForestClassifier(n_estimators=20,
random_state=RandomState(MT19937) at 0x7F2C1F1F5440),
factor=2,
param_distributions={'bootstrap': [True, False],
'criterion': ['gini', 'entropy'],
'max_depth': [3, None],
'max_features': <scipy.stats._distn_infrastructure.rv_frozen object at 0x7f2ba4e36a60>,
'min_samples_split': <scipy.stats._distn_infrastructure.rv_frozen object at 0x7f2c30cdda60>},
random_state=RandomState(MT19937) at 0x7F2C1F1F5440,
refit=<function _refit_callable at 0x7f2c35558790>)
Ahora podemos utilizar el atributo cv_results_ del estimador de búsqueda para inspeccionar y graficar la evolución de la búsqueda.
results = pd.DataFrame(rsh.cv_results_)
results['params_str'] = results.params.apply(str)
results.drop_duplicates(subset=('params_str', 'iter'), inplace=True)
mean_scores = results.pivot(index='iter', columns='params_str',
values='mean_test_score')
ax = mean_scores.plot(legend=False, alpha=.6)
labels = [
f'iter={i}\nn_samples={rsh.n_resources_[i]}\n'
f'n_candidates={rsh.n_candidates_[i]}'
for i in range(rsh.n_iterations_)
]
ax.set_xticks(range(rsh.n_iterations_))
ax.set_xticklabels(labels, rotation=45, multialignment='left')
ax.set_title('Scores of candidates over iterations')
ax.set_ylabel('mean test score', fontsize=15)
ax.set_xlabel('iterations', fontsize=15)
plt.tight_layout()
plt.show()
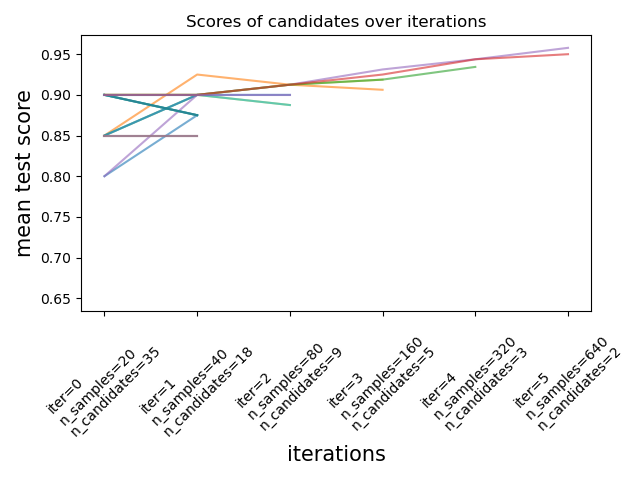
Número de candidatos y cantidad de recursos en cada iteración¶
En la primera iteración, se utiliza una pequeña cantidad de recursos. El recurso aquí es el número de muestras con las que se entrenan los estimadores. Se evalúan todos los candidatos.
En la segunda iteración, sólo se evalúa la mejor mitad de los candidatos. El número de recursos asignados se duplica: los candidatos se evalúan en el doble de muestras.
Este proceso se repite hasta la última iteración, en la que sólo quedan 2 candidatos. El mejor candidato es el que tiene la mejor puntuación en la última iteración.
Tiempo total de ejecución del script: (0 minutos 9.623 segundos)