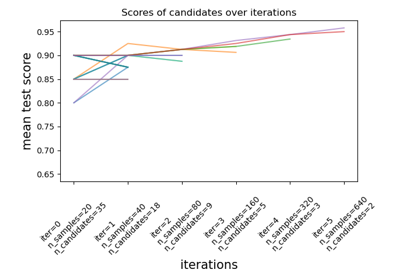
sklearn.model_selection.HalvingRandomSearchCV¶
- class sklearn.model_selection.HalvingRandomSearchCV¶
Búsqueda aleatoria de hiperparámetros.
La estrategia de búsqueda comienza a evaluar todos los candidatos con una pequeña cantidad de recursos y selecciona iterativamente los mejores candidatos, utilizando cada vez más recursos.
Los candidatos se muestrean de forma aleatoria del espacio de parámetros y el número de candidatos muestreados se determina por
n_candidates.Lee más en el Manual del usuario.
Nota
Este estimador es todavía experimental por ahora: las predicciones y la API podrían cambiar sin ningún ciclo de obsolescencia. Para utilizarlo, es necesario importar explícitamente
enable_halving_search_cv:>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_halving_search_cv # noqa >>> # now you can import normally from model_selection >>> from sklearn.model_selection import HalvingRandomSearchCV
- Parámetros
- estimatorestimator object.
Se supone que implementa la interfaz del estimador de scikit-learn. O bien el estimador necesita proporcionar una función
score, o se debe pasarscoring.- param_distributionsdict
Diccionario con nombres de parámetros (cadenas) como claves y distribuciones o listas de parámetros a probar. Las distribuciones deben proporcionar un método
rvspara el muestreo (como los de scipy.stats.distributions). Si se da una lista, se muestrea uniformemente.- n_candidatesint, default=”exhaust”
El número de parámetros candidatos a muestrear, en la primera iteración. Si se utiliza “exhaust” se muestrearán suficientes candidatos para que la última iteración utilice tantos recursos como sea posible, basándose en
min_resources,max_resourcesyfactor. En este caso,min_resourcesno puede ser “exhaust”.- factorint o float, default=3
El parámetro “halving”, que determina la proporción de candidatos que se seleccionan en cada iteración posterior. Por ejemplo,
factor=3significa que sólo se selecciona un tercio de los candidatos.- resource :
'n_samples'o str, default=”n_samples”“n_samples” o str, default=”n_samples” Define el recurso que aumenta con cada iteración. Por defecto, el recurso es el número de muestras. También puede establecerse en cualquier parámetro del estimador base que acepte valores enteros positivos, por ejemplo, “n_iterations” o “n_estimators” para un estimador de potenciación de gradiente. En este caso,
max_resourcesno puede ser “auto” y debe establecerse explícitamente.- max_resourcesint, default=”auto”
El número máximo de recursos que se permite utilizar a cualquier candidato para una iteración determinada. Por defecto, se establece en
n_samplescuandoresource='n_samples'(por defecto), de lo contrario se produce un error.- min_resources{“exhaust”, “smallest”} o int, default=”smallest”
La cantidad mínima de recursos que cualquier candidato puede utilizar en una iteración determinada. Equivalentemente, define la cantidad de recursos
r0que se asigna a cada candidato en la primera iteración.- “smallest” es una heurística que establece
r0en un valor pequeño: n_splits * 2cuandoresource='n_samples'para una regresiónproblema
n_classes * n_splits * 2cuandoresource='n_samples'para unproblema de clasificación
1cuandoresource != 'n_samples'
- “smallest” es una heurística que establece
“exhaust” establecerá «r0» de forma que la última iteración utilice tantos recursos como sea posible. Es decir, la última iteración utilizará el mayor valor menor que
max_resourcesque sea múltiplo demin_resourcesyfactor. En general, el uso de “exhaust” conduce a un estimador más preciso, pero consumpero es ligeramente más lento. El uso de “exhaust” no está disponible cuandon_candidates='exhaust'.
Ten en cuenta que la cantidad de recursos utilizados en cada iteración es siempre un múltiplo de
min_resources.- aggressive_eliminationbool, default=False
Esto sólo es relevante en los casos en los que no hay suficientes recursos para reducir los candidatos restantes a un máximo de
factordespués de la última iteración. Si esTrue, el proceso de búsqueda “repetirá” la primera iteración durante el tiempo necesario hasta que el número de candidatos sea lo suficientemente pequeño. Por defecto esFalse, lo que significa que la última iteración puede evaluar más candidatos quefactor. Consulta Eliminación agresiva de candidatos para más detalles.- cvint, generador de validación cruzada o un iterable, default=5
Determina la estrategia de división de la validación cruzada. Las posibles entradas para cv son:
entero, para especificar el número de pliegues en un
(Stratified)KFold,Un iterable que produce divisiones (train, test) como arreglos de índices.
Para entradas enteras/None, si el estimador es un clasificador e
yes binario o multiclase, se utilizaStratifiedKFold. En todos los demás casos, se utilizaKFold.Consulta el Manual de usuario para las diversas estrategias de validación cruzada que pueden ser utilizadas aquí.
Nota
Debido a los detalles de implementación, los pliegues producidos por
cvdeben ser los mismos a través de múltiples invocaciones acv.split(). Para los iteradores incorporados descikit-learn, esto se puede lograr desactivando el mezclado (shuffle=False), o estableciendo el parámetrorandom_statedecven un número entero.- scoringstring, invocable, o None, default=None
Una sola cadena (ver El parámetro scoring: definir las reglas de evaluación del modelo) o un invocable «callable» (ver Definir tu estrategia de puntuación a partir de funciones métricas) para evaluar las predicciones en el conjunto de pruebas. Si es None, se utiliza el método score del estimador.
- refitbool, default=True
Si es True, reajusta un estimador utilizando los mejores parámetros encontrados en todo el conjunto de datos.
El estimador reajustado está disponible en el atributo
best_estimator_y permite utilizarpredictdirectamente en esta instanciaHalvingRandomSearchCV.- error_score“raise” o numeric
Valor para asignar a la puntuación (score) si se produce un error en el ajuste del estimador. Si se establece en “raise”, se genera un error. Si se da un valor numérico, se genera FitFailedWarning. Este parámetro no afecta al paso de reajuste, que siempre generará el error. Por defecto es
np.nan- return_train_scorebool, default=False
Si es
False, el atributocv_results_no incluirá las puntuaciones de entrenamiento. El cálculo de las puntuaciones de entrenamiento se utiliza para obtener información sobre el impacto de los diferentes ajustes de los parámetros en el equilibrio entre sobreajuste/subajuste. Sin embargo, calcular las puntuaciones en el conjunto de entrenamiento puede ser costoso computacionalmente y no es estrictamente necesario para seleccionar los parámetros que producen el mejor rendimiento de generalización.- random_stateint, RandomState instance o None, default=None
Estado del generador de números pseudoaleatorios utilizado para el submuestreo del conjunto de datos cuando
resources != 'n_samples'. También se utiliza para el muestreo uniforme aleatorio de las listas de valores posibles en lugar de las distribuciones de scipy.stats. Pasa un número entero (int) para una salida reproducible a través de múltiples invocaiones a la función. Ver Glosario.- n_jobsint o None, default=None
Número de trabajos a ejecutar en paralelo.
Nonesignifica 1 a menos que esté en un contextojoblib.parallel_backend.-1significa utilizar todos los procesadores. Ver Glosario para más detalles.- verboseint
Controla la verbosidad: cuanto más alta, más mensajes.
- Atributos
- n_resources_list de int
La cantidad de recursos utilizados en cada iteración.
- n_candidates_list de int
El número de parámetros candidatos que se evaluaron en cada iteración.
- n_remaining_candidates_int
El número de parámetros candidatos que quedan después de la última iteración. Corresponde a
ceil(n_candidates[-1] / factor)- max_resources_int
El número máximo de recursos que cualquier candidato puede utilizar en una iteración determinada. Ten en cuenta que, dado que el número de recursos utilizados en cada iteración debe ser un múltiplo de
min_resources_, el número real de recursos utilizados en la última iteración puede ser menor quemax_resources_.- min_resources_int
La cantidad de recursos que se asignan a cada candidato en la primera iteración.
- n_iterations_int
El número real de iteraciones que se ejecutaron. Es igual a
n_required_iterations_siaggressive_eliminationesTrue. De lo contrario, es igual amin(n_possible_iterations_, n_required_iterations_).- n_possible_iterations_int
El número de iteraciones que son posibles comenzando con los recursos
min_resources_y sin superar los recursosmax_resources_.- n_required_iterations_int
El número de iteraciones que se requieren para terminar con menos de
factorcandidatos en la última iteración, comenzando conmin_resources_recursos. Será menor quen_possible_iterations_cuando no haya suficientes recursos.- cv_results_dict de numpy (masked) ndarrays
Un diccionario (dict) con claves como cabeceras de columna y valores como columnas, que puede ser importado en un
DataFramede pandas. Contiene mucha información para analizar los resultados de una búsqueda. Por favor, consulta el Manual de Usuario para más detalles.- best_estimator_estimator o dict
Estimador que fue elegido por la búsqueda, es decir, el estimador que dio la puntuación más alta (o la pérdida más pequeña si se especifica) en los datos omitidos. No está disponible si
refit = False”.- best_score_float
Puntuación media de la validación cruzada del mejor estimador (best_estimator).
- best_params_dict
Configuración del parámetro que dio los mejores resultados en los datos retenidos.
- best_index_int
El índice (de los arreglos
cv_results_) que corresponde a la mejor configuración del parámetro candidato.El diccionario (dict) en
search.cv_results_['params'][search.best_index_]da la configuración de parámetros para el mejor modelo, que da la puntuación media más alta (search.best_score_).- scorer_function o un dict
Función de puntuación utilizada en los datos retenidos para elegir los mejores parámetros para el modelo.
- n_splits_int
El número de divisiones de la validación cruzada (pliegues/iteraciones).
- refit_time_float
Segundos utilizados para reajustar el mejor modelo en todo el conjunto de datos.
Esto está presente sólo si
refitno es False.
Ver también
HalvingGridSearchCVBúsqueda sobre una cuadrícula de parámetros utilizando una división sucesiva a la mitad.
Notas
Los parámetros seleccionados son los que maximizan la puntuación de los datos retenidos, según el parámetro de puntuación.
Ejemplos
>>> from sklearn.datasets import load_iris >>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.experimental import enable_halving_search_cv # noqa >>> from sklearn.model_selection import HalvingRandomSearchCV >>> from scipy.stats import randint ... >>> X, y = load_iris(return_X_y=True) >>> clf = RandomForestClassifier(random_state=0) >>> np.random.seed(0) ... >>> param_distributions = {"max_depth": [3, None], ... "min_samples_split": randint(2, 11)} >>> search = HalvingRandomSearchCV(clf, param_distributions, ... resource='n_estimators', ... max_resources=10, ... random_state=0).fit(X, y) >>> search.best_params_ {'max_depth': None, 'min_samples_split': 10, 'n_estimators': 9}
Métodos
Invoca a decision_function en el estimador con los mejores parámetros encontrados.
Ejecuta el ajuste con todos los conjuntos de parámetros.
Obtiene los parámetros para este estimador.
Invoca a inverse_transform en el estimador con los mejores parámetros encontrados.
Invoca a predict en el estimador con los mejores parámetros encontrados.
Invoca a predict_log_proba en el estimador con los mejores parámetros encontrados.
Invoca a predict_proba en el estimador con los mejores parámetros encontrados.
Devuelve la puntuación en los datos dados, si el estimador ha sido reajustado.
Invoca a score_samples en el estimador con los mejores parámetros encontrados.
Establece los parámetros de este estimador.
Invoca a transform en el estimador con los mejores parámetros encontrados.
- decision_function()¶
Invoca a decision_function en el estimador con los mejores parámetros encontrados.
Sólo está disponible si
refit=Truey el estimador subyacente admitedecision_function.- Parámetros
- Xindexable, length n_samples
Debe cumplir los supuestos de entrada del estimador subyacente.
- fit()¶
Ejecuta el ajuste con todos los conjuntos de parámetros.
- Parámetros
- Xarray-like, forma (n_samples, n_features)
Vector de entrenamiento, donde
n_sampleses el número de muestras yn_featureses el número de características.- yarray-like, forma (n_samples,) o (n_samples, n_output), opcional
Objetivo relativo a X para la clasificación o la regresión; None para el aprendizaje no supervisado.
- groupsarray-like de forma (n_samples,), default=None
Etiquetas de grupo para las muestras utilizadas al dividir el conjunto de datos en conjunto de entrenamiento/prueba. Sólo se utiliza junto con una instancia cv «Group» (por ejemplo,
GroupKFold).- **fit_paramsdict of string -> object
Parámetros pasados al método
fitdel estimador
- get_params()¶
Obtiene los parámetros para este estimador.
- Parámetros
- deepbool, default=True
Si es True, devolverá los parámetros para este estimador y los subobjetos contenidos que son estimadores.
- Devuelve
- paramsdict
Nombres de los parámetros mapeados a sus valores.
- inverse_transform()¶
Invoca a inverse_transform en el estimador con los mejores parámetros encontrados.
Sólo está disponible si el estimador subyacente implementa
inverse_transformyrefit=True.- Parámetros
- Xtindexable, length n_samples
Debe cumplir los supuestos de entrada del estimador subyacente.
- predict()¶
Invoca a predict en el estimador con los mejores parámetros encontrados.
Sólo está disponible si
refit=Truey el estimador subyacente admitepredict.- Parámetros
- Xindexable, length n_samples
Debe cumplir los supuestos de entrada del estimador subyacente.
- predict_log_proba()¶
Invoca a predict_log_proba en el estimador con los mejores parámetros encontrados.
Sólo está disponible si
refit=Truey el estimador subyacente admitepredict_log_proba.- Parámetros
- Xindexable, length n_samples
Debe cumplir los supuestos de entrada del estimador subyacente.
- predict_proba()¶
Invoca a predict_proba en el estimador con los mejores parámetros encontrados.
Sólo está disponible si
refit=Truey el estimador subyacente admitepredict_proba.- Parámetros
- Xindexable, length n_samples
Debe cumplir los supuestos de entrada del estimador subyacente.
- score()¶
Devuelve la puntuación en los datos dados, si el estimador ha sido reajustado.
Esto utiliza la puntuación definida por
scoringcuando se proporciona, y el métodobest_estimator_.scoreen caso contrario.- Parámetros
- Xarray-like de forma (n_samples, n_features)
Datos de entrada, donde n_samples es el número de muestras y n_features es el número de características.
- yarray-like de forma (n_samples, n_output) o (n_samples,), default=None
Objetivo relativo a X para la clasificación o la regresión; None para el aprendizaje no supervisado.
- Devuelve
- scorefloat
- score_samples()¶
Invoca a score_samples en el estimador con los mejores parámetros encontrados.
Sólo está disponible si
refit=Truey el estimador subyacente admitescore_samples.Nuevo en la versión 0.24.
- Parámetros
- Xiterable
Datos para predecir. Deben cumplir los requisitos de entrada del estimador subyacente.
- Devuelve
- y_scorendarray de forma (n_samples,)
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto en estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma<component>__<parameter>para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia del estimador
Instancia del estimador.
- transform()¶
Invoca a transform en el estimador con los mejores parámetros encontrados.
Sólo está disponible si el estimador subyacente admite
transformyrefit=True.- Parámetros
- Xindexable, length n_samples
Debe cumplir los supuestos de entrada del estimador subyacente.