Nota
Haz clic aquí para descargar el código completo del ejemplo o para ejecutar este ejemplo en tu navegador a través de Binder
Sobreajuste vs Subajuste¶
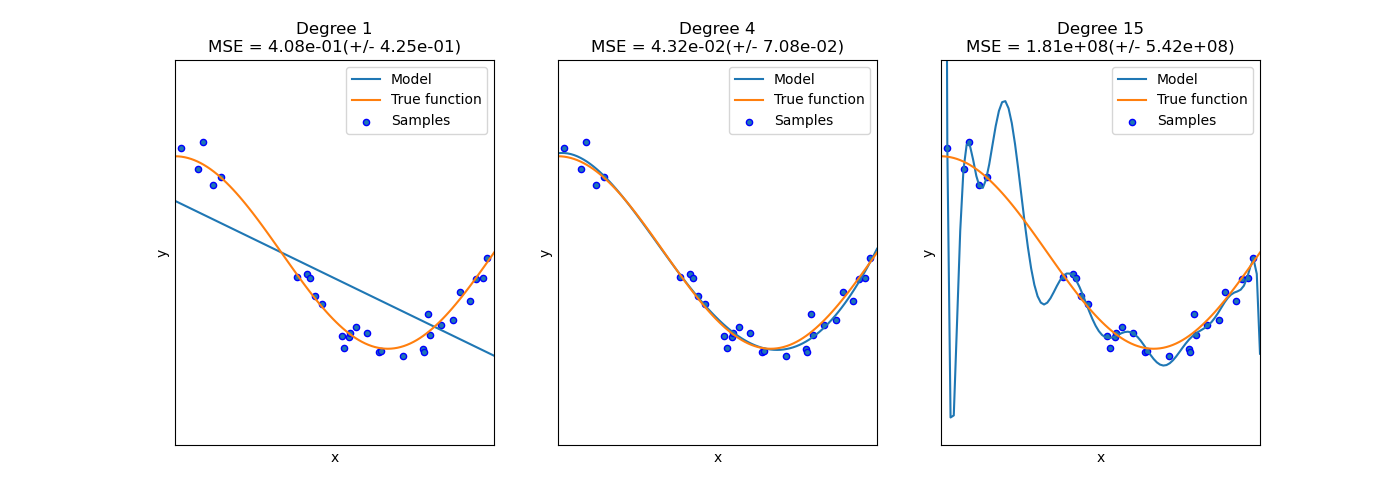
Este ejemplo demuestra los problemas de subajuste y sobreajuste y cómo podemos utilizar la regresión lineal con características polinomiales para aproximar funciones no lineales. El gráfico muestra la función que queremos aproximar, que es una parte de la función coseno. Además, se muestran las muestras de la función real y las aproximaciones de diferentes modelos. Los modelos tienen características polinomiales de diferentes grados. Podemos ver que una función lineal (polinomio de grado 1) no es suficiente para ajustarse a las muestras de entrenamiento. Esto se llama subajuste. Un polinomio de grado 4 se aproxima casi perfectamente a la función verdadera. Sin embargo, para grados superiores el modelo se sobreajusta a los datos de entrenamiento, es decir, aprende el ruido de los datos de entrenamiento. Evaluamos cuantitativamente el sobreajuste / subajuste utilizando la validación cruzada. Calculamos el error cuadrático medio (MSE) en el conjunto de validación; cuanto más alto, menos probable es que el modelo generalice correctamente a partir de los datos de entrenamiento.
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
def true_fun(X):
return np.cos(1.5 * np.pi * X)
np.random.seed(0)
n_samples = 30
degrees = [1, 4, 15]
X = np.sort(np.random.rand(n_samples))
y = true_fun(X) + np.random.randn(n_samples) * 0.1
plt.figure(figsize=(14, 5))
for i in range(len(degrees)):
ax = plt.subplot(1, len(degrees), i + 1)
plt.setp(ax, xticks=(), yticks=())
polynomial_features = PolynomialFeatures(degree=degrees[i],
include_bias=False)
linear_regression = LinearRegression()
pipeline = Pipeline([("polynomial_features", polynomial_features),
("linear_regression", linear_regression)])
pipeline.fit(X[:, np.newaxis], y)
# Evaluate the models using crossvalidation
scores = cross_val_score(pipeline, X[:, np.newaxis], y,
scoring="neg_mean_squared_error", cv=10)
X_test = np.linspace(0, 1, 100)
plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model")
plt.plot(X_test, true_fun(X_test), label="True function")
plt.scatter(X, y, edgecolor='b', s=20, label="Samples")
plt.xlabel("x")
plt.ylabel("y")
plt.xlim((0, 1))
plt.ylim((-2, 2))
plt.legend(loc="best")
plt.title("Degree {}\nMSE = {:.2e}(+/- {:.2e})".format(
degrees[i], -scores.mean(), scores.std()))
plt.show()
Tiempo total de ejecución del script: (0 minutos 0.275 segundos)