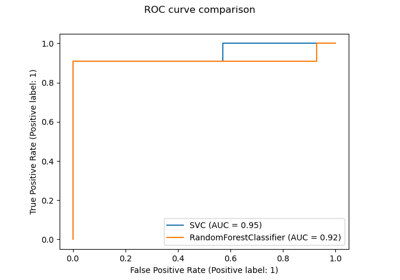
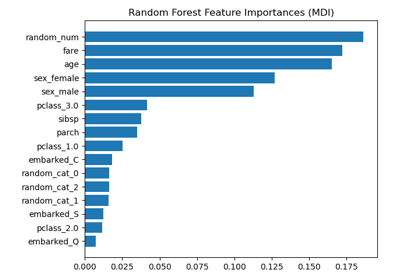
sklearn.inspection.permutation_importance¶
- sklearn.inspection.permutation_importance()¶
Importancia de la permutación para la evaluación de la característica [BRE].
Se requiere que el estimator sea un estimador ajustado.`X` puede ser el conjunto de datos utilizado para entrenar el estimador o un conjunto retenido. La importancia de la permutación de una característica se calcula como sigue. En primer lugar, se evalúa una métrica de referencia, definida por scoring, en un conjunto de datos (potencialmente diferente) definido por
X. A continuación, se permuta una columna de características del conjunto de validación y se evalúa de nuevo la métrica. La importancia de la permutación se define como la diferencia entre la métrica de referencia y la métrica de la permutación de la columna de características.Más información en el Manual de usuario.
- Parámetros
- estimatorobject
Un estimador que ya ha sido fitted y es compatible con scorer.
- Xndarray o DataFrame, forma (n_samples, n_features)
Datos sobre los que se calculará la importancia de la permutación.
- yarray-like o None, forma (n_samples, ) o (n_samples, n_classes)
Objetivos para los supervisados o
Nonepara los no supervisados.- scoringcadena, invocable o None, default=None
Calificador a utilizar. Puede ser una sola cadena ( consulta El parámetro scoring: definir las reglas de evaluación del modelo) o una llamada (consulta Definir tu estrategia de puntuación a partir de funciones métricas). Si es None, se utiliza el puntuador predeterminado del estimador.
- n_repeatsint, default=5
Número de veces para permutar una característica.
- n_jobsentero o None, default=None
Número de trabajos a ejecutar en paralelo. El cálculo se realiza computando la puntuación de permutación para cada columna y paralelizando sobre las columnas.
Nonesignifica 1 a menos que esté en un contextojoblib.parallel_backend.-1significa que se utilizan todos los procesadores. Ver Glosario para más detalles.- random_stateentero, instancia de RandomState, default=None
Generador de números pseudoaleatorios para controlar las permutaciones de cada función. Pasa un int para obtener resultados reproducibles a través de las llamadas a la función. Ver :term:
Glosario<random_state>.- sample_weightarray-like de forma (n_samples,), default=None
Pesos de muestra utilizados en la puntuación.
Nuevo en la versión 0.24.
- Devuelve
- result
Bunch Objeto tipo diccionario, con los siguientes atributos.
- importances_meanndarray, forma (n_features, )
Media de la importancia de la característica sobre
n_repeats.- importances_stdndarray, forma (n_features, )
Desviación estándar sobre
n_repeats.- importancesndarray, forma (n_features, n_repeats)
Puntuaciones de importancia de permutación en bruto.
- result
Referencias
- BRE
L. Breiman, «Random Forests», Machine Learning, 45(1), 5-32, 2001. https://doi.org/10.1023/A:1010933404324
Ejemplos
>>> from sklearn.linear_model import LogisticRegression >>> from sklearn.inspection import permutation_importance >>> X = [[1, 9, 9],[1, 9, 9],[1, 9, 9], ... [0, 9, 9],[0, 9, 9],[0, 9, 9]] >>> y = [1, 1, 1, 0, 0, 0] >>> clf = LogisticRegression().fit(X, y) >>> result = permutation_importance(clf, X, y, n_repeats=10, ... random_state=0) >>> result.importances_mean array([0.4666..., 0. , 0. ]) >>> result.importances_std array([0.2211..., 0. , 0. ])