sklearn.mixture es un paquete que permite aprender Modelos de Mezcla Gaussiana (matrices diagonales, esféricas, enlazadas y de completa covarianza soportadas), su muestreo, y estimarlos desde los datos. También se proporcionan facultades para ayudar a determinar el número apropiado de componentes.
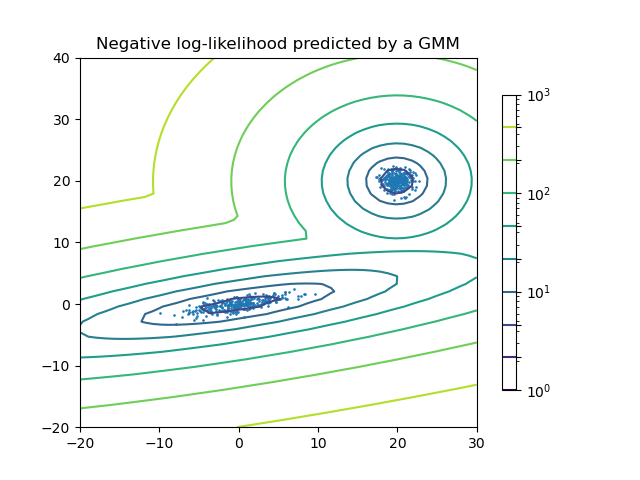
Modelo de mezcla Gaussiana de dos componentes:puntos de datos, y superficies de probabilidad equiparables al modelo.¶
Un modelo de mezcla Gaussiana es un modelo probabilístico que asume que todos los puntos de datos son generados de una mezcla de un número finito de distribuciones Gaussianas con parámetros desconocidos. Uno puede pensar en los modelos de mezcla como la generalización de agrupamiento k-medias para incorporar información acerca de tanto la estructura de covarianza de los datos como los centros de las Gaussianas latentes.
Scikit-learn implementa diferentes clases para estimar modelos de mezcla Gaussiana, que corresponden a diferentes estrategias de estimación, detalladas a continuación.
El objeto GaussianMixture implementa el algoritmo expectation-maximization (EM) para el encaje de modelos mezcla-de-Gaussianos. Puede también dibujar elipsoides de confidencia para modelos multivariante, y calcular el Criterio de Información Bayesiano para estimar el número de clústers en los datos. Se proporciona un método GaussianMixture.fit que aprende un modelo de mezcla Gaussiana de los datos de entrenamiento. Dados ciertos datos de prueba, se puede asignar a cada muestra el Gaussiano al que probablemente pertenezca usando el método GaussianMixture.predict.
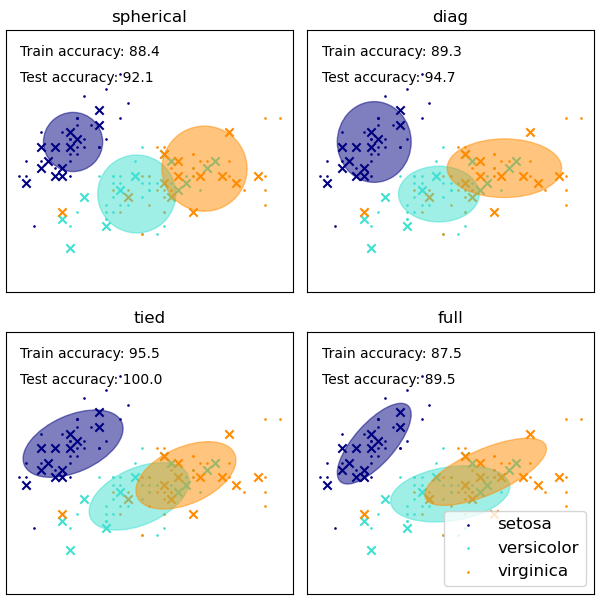
La GaussianMixture viene con diferentes opciones para restringir la covarianza de las clases de diferencia estimadas: esférico, diagonal, empatado o covarianza completa.
Ejemplos:
Vea Covarianzas GMM para un ejemplo del uso de la mezcla Gaussiana como agrupamiento en el conjunto de datos iris.
Es el algoritmo más rápido para aprender modelos de mezcla
Agnóstico
Ya que este algoritmo solo maximiza la probabilidad, no sesgará los medios hacia cero, ni sesgará los tamaños de clúster para tener estructuras especificas que podrían o no aplicar.
Cuando uno tiene insuficientes puntos por mezcla, estimar las matrices de covarianza se vuelve difícil, y se sabe que el algoritmo diverge y encuentra soluciones con probabilidades infinitas a menos que uno regularice las covarianzas artificialmente.
Número de componentes
Este algoritmo siempre utilizará todos los componentes a los que tiene acceso, necesitando criterios teóricos de apartado de datos o información para decidir cuantos componentes usar en la ausencia de señas externas.
2.1.1.2. Seleccionando el número de componentes en un modelo clásico de mezcla de Gaussianos¶
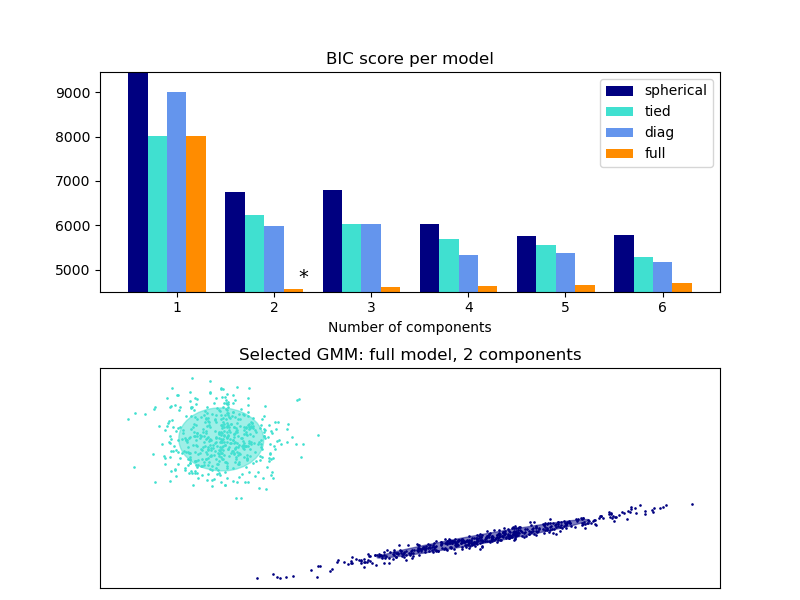
El criterio de BIC puede ser utilizado para seleccionar el número de componentes en una mezcla Gaussiana de una manera eficiente. En teoría, recupera el verdadero número de componentes solo en el régimen asíntota (es decir, si muchos datos son disponibles y suponiendo que los datos fueron generados i.i.d. desde una mezcla de distribución Gaussiana). Ten en cuenta que utilizar una Variational Bayesian Gaussian mixture evita la especificación del número de componentes para un modelo de mezcla Gaussiana.
2.1.1.3. Algoritmo de estimación Esperanza-maximización¶
La dificultad principal en aprender modelos de mezcla Gaussiana desde datos sin etiquetar, es que uno usualmente no sabe cuales puntos vinieron de qué componente latente (si uno tiene acceso a esta información, se vuelve muy fácil encajar una distribución Gaussiana separada para cada conjunto de puntos). Esperanza-maximización es un algoritmo estadístico bien fundamentado que evita este problema mediante un proceso iterativo. Primero uno asume que componentes aleatorios (centrados aleatoriamente en puntos de datos, aprendidos de k-medias, o inclusive solo distribuidos normalmente alrededor del origen) y calcula por cada punto una probabilidad de ser generado por cada componente del modelo. Y entonces, uno ajusta los parámetros para maximizar la probabilidad de los datos dadas esas asignaciones. La repetición este proceso está garantizada a siempre converger a un óptimo local.
El objeto BayesianGaussianMixture implementa una variante del modelo de mezcla Gaussiana con algoritmos de inferencia variacionales. La API es similar a la definida por GaussianMixture.
2.1.2.1. Algoritmo de estimación: inferencia variacional¶
La inferencia variacional es una extensión de la esperanza-maximización que maximiza un limite inferior en la evidencia del modelo (incluyendo los priores) en lugar de la probabilidad de datos. El principio detrás de los métodos variacionales es el mismo que en la esperanza-maximización (es decir, ambos son algoritmos iterativos que alternan entre encontrar las probabilidades de cada punto a ser generadas por cada mezcla y encajar la mezcla a estos puntos asignados), pero los métodos variacionales añaden regularización mediante la integración de información desde distribuciones priores. Esto evita las singularidades comúnmente encontradas en soluciones de esperanza-maximización pero introduce algunos sesgos sutiles al modelo. La inferencia suele ser notablemente mas lenta, pero no tanto como para que su uso sea impráctico.
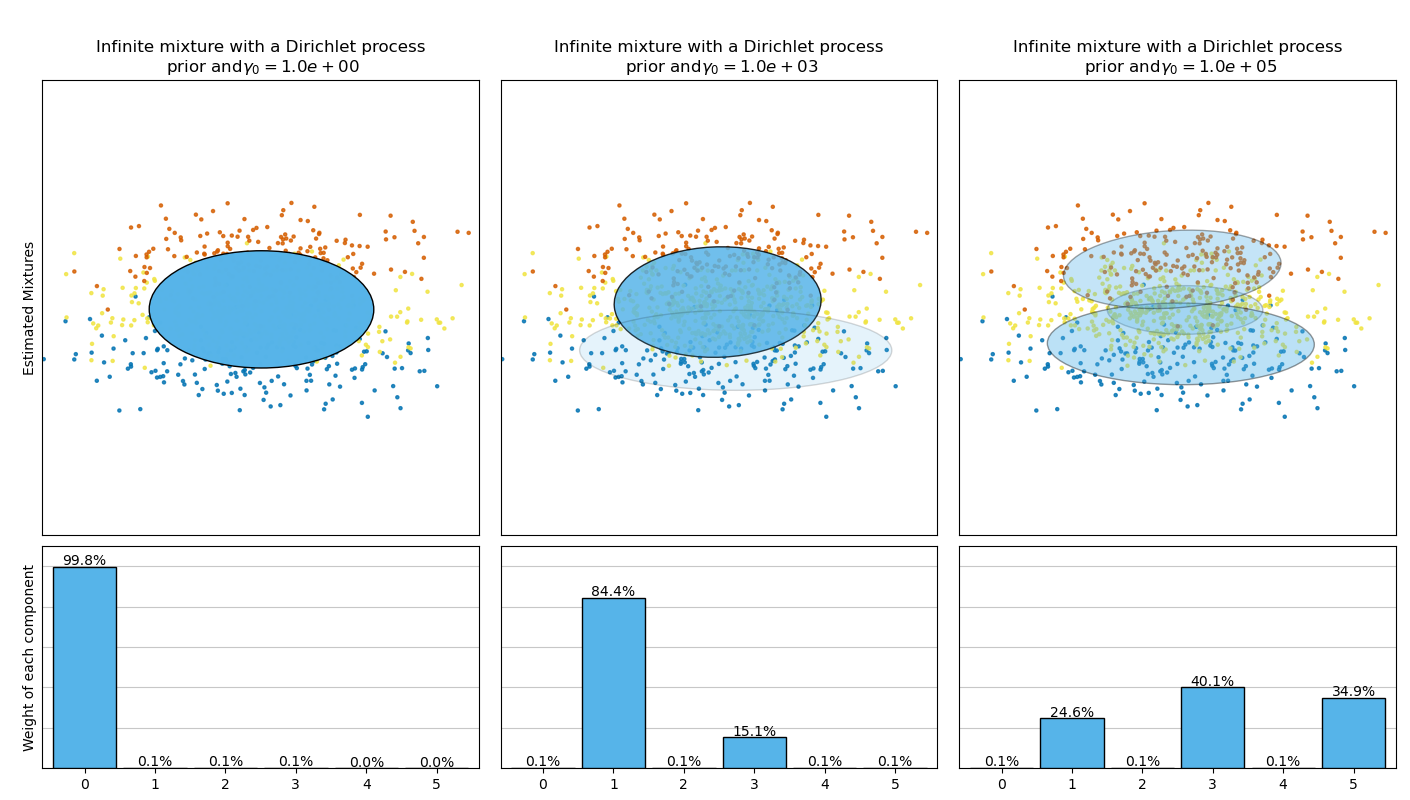
Debido a su naturaleza bayesiana, el algoritmo necesita mas hiperparámetros que la esperanza-maximización, el mas importante de estos siendo el parámetro de concentración weight_concentration_prior. Especificar un valor bajo para la concentración previa hará que el modelo ponga la mayor parte del ponderado en pocos componentes y que establezca el ponderado del resto de los componentes muy cerca de 0. Si se usan valores altos para la concentración previa, se permitirá que un número más grande de componentes sea activo en la mezcla.
La implementación de parámetros de la clase BayesianGaussianMixture propone dos tipos de previos para la distribución de ponderados: un modelo de mezcla finita con distribución Dirichlet y un modelo de mezcla infinita con el proceso Dirichlet. En la práctica, el algoritmo de inferencia del Proceso Dirichlet es aproximado y utiliza una distribución truncada con un número máximo de componentes fijo (llamada la representación rompe-palos). El número de componentes realmente utilizados casi siempre depende de los datos.
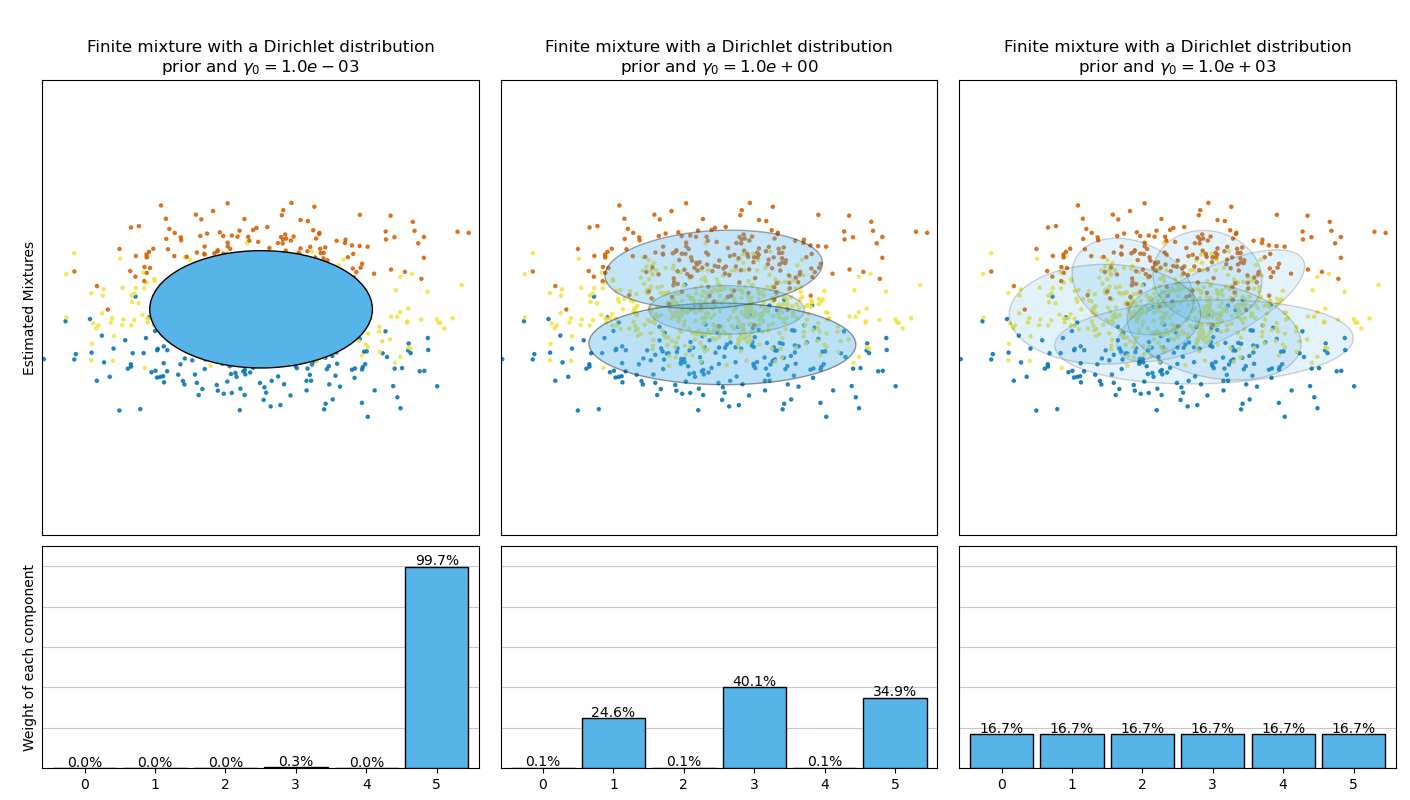
La siguiente figura compara los resultados obtenidos para distintos tipos del previo de ponderado de concentración (el parámetro weight_concentration_prior_type) para distintos valores de weight_concentration_prior. Aquí podemos observar que el valor de parámetro weight_concentration_prior tiene un fuerte impacto en el número efectivo de componentes activos obtenido. Podemos también notar que valores grandes para el ponderado de concentración llevan a ponderados mas uniformes cuando el tipo de previo es “dirichlet_distribution” mientras que esto no es necesariamente el caso para el tipo “dirichlet_process” (usado por defecto).
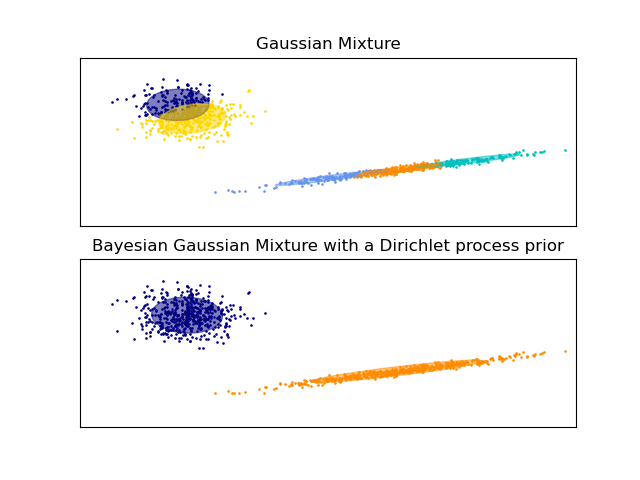
Los ejemplos a continuación comparan los modelos de mezcla Gaussiana con un número fijo de componentes, a los modelos de mezcla Gaussiana variacional con un proceso Dirichlet a priori. Aquí, una mezcla Gaussiana clásica es ajustada con 5 componentes en un conjunto de datos compuesto de 2 clústers. Podemos ver que la mezcla variacional Gaussiana con un proceso Dirichlet a priori es capaz de limitarse a si misma a solo 2 componentes, mientras que la mezcla Gaussiana ajusta los datos con un número fijo de componentes que tiene que ser establecido a priori por el usuario: En este caso el usuario ha seleccionado n_componentes=5 lo cual no corresponde a la distribución generativa real de este conjunto de datos de juguete. Ten en cuenta que con muy pocas observaciones, los modelos de mezcla Gaussiana variacional con un proceso Dirichlet a priori puede tomar una postura conservadora, y ajustar solo un componente.
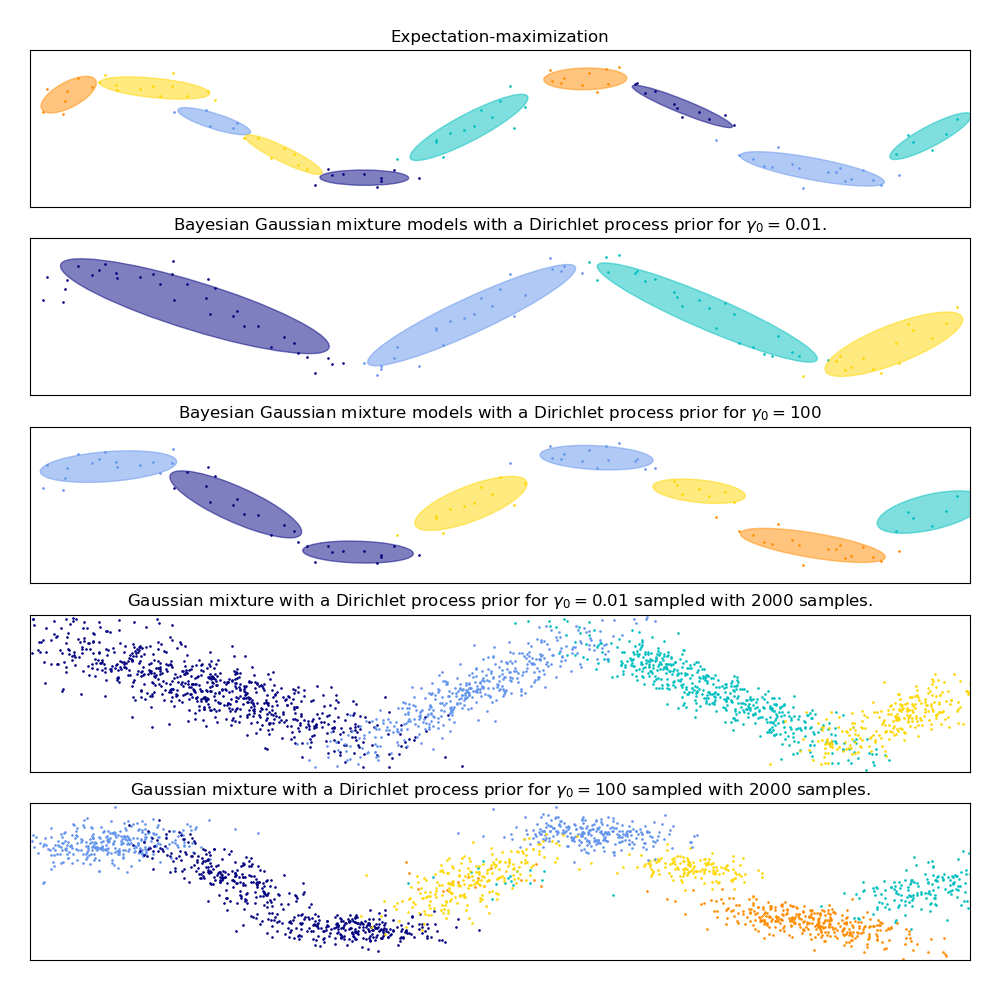
En la siguiente figura estamos encajando un conjuntos de datos que no está bien representado por una mezcla gaussiana. Ajustando el parámetro weight_concentration_prior del BayesianGaussianMixture controlamos el número de componentes usados para ajustar estos datos. También presentamos en las ultimas dos gráficas un muestreo aleatorio generado de las dos mezclas resultantes.
cuando weight_concentration_prior es lo suficientemente pequeño y n_components es mas grande que lo que el modelo considera necesario, el modelo de mezcla Bayesiana variacional tiene una tendencia natural a establecer algunos valores de ponderados de mezcla cerca de cero. Esto hace posible dejar que el modelo escoja un número adecuado de componentes efectivos automáticamente. Solo se necesita proporcionar un limite superior de este número. Sin embargo, tome en cuenta que el número «ideal» de componentes activos depende mucho de la aplicación y suele estar mal definido en una configuración de exploración de datos.
Menor sensibilidad al número de parámetros
a diferencia de los modelos finitos, que casi siempre usarán tantos componentes como puedan, y, por lo tanto, producirán soluciones incontroladamente diferentes para diferentes números de componentes, la inferencia variacional con un proceso Dirichlet previo (weight_concentration_prior_type='dirichlet_process') no cambiará mucho con los cambios en los parámetros, lo que llevará a mayor estabilidad y menos ajustamiento.
Regularización
debido a la incorporación de información previa, las soluciones variacionales presentan menos casos especiales patológicos que las soluciones de esperanza-maximización.
la parametrización adicional necesaria para la inferencia variacional hace que la inferencia sea más lenta, aunque no mucho.
Hiperparámetros
este algoritmo necesita un hiperparámetro adicional que quizás necesite ajustes experimentales mediante una validación cruzada.
Sesgo
hay muchos sesgos impícitos en los algoritmos de inferencia (y también en el proceso de Dirichlet si se utiliza), y cada vez que hay un desajuste entre estos sesgos y los datos quizás sea posible encajar mejores modelos utilizando una mezcla finita.
Aquí describimos los algoritmos de inferencia variacional en una mezcla de procesos de Dirichlet. El proceso de Dirichlet es una distribución de probabilidad previa en agrupaciones con un número infinito, sin limite alguno, de particiones. Las técnicas variacionales nos deja incorporar esta estructura previa en modelos de mezcla Gaussiana sin casi ningun costo en tiempo de inferencia, comparado a un modelo de mezcla Gaussiana finita.
Una pregunta importante es cómo el proceso de Dirichlet puede usar un número infinito y sin límites de agrupaciones e igualmente ser consistente. Mientras que una explicación completa no encaja dentro de este manual, uno puede pensar en la analogía de su proceso rompe-palos para ayudar a entenderlo. El proceso rompe-palos es una historia generativa para el proceso de Dirichlet. Empezamos con un palo de longitud unitaria y en cada paso partimos una porción del palo restante, asociando la longitud de la porción del palo a la proporción de puntos que cae dentro de un grupo de la mezcla. Al final, para representar la mezcla infinita, asociamos la ultima porción restante del palo a la proporción de puntos que no caen en todos los demás grupos. La longitud de cada pieza es una variable aleatoria con una probabilidad proporcional al parámetro de concentración. Un valor más pequeño de la concentración dividirá la longitud unitaria en porciones más grandes del palo (definiendo una distribución mas concentrada). Valores de concentración mas grandes crearan pedazos mas pequeños del palo (incrementando el número de componentes con ponderados que no sean cero).
Las técnicas de inferencia variacional para el proceso de Dirichlet todavía funcionan con una aproximación finita a este modelo de mezcla infinita, pero en lugar de tener que especificar a priori cuántos componentes se desean usar, solo se especifica el parámetro de concentración y un límite superior en el número de componentes de mezcla (este límite superior, asumiendo que queda más alto que el «verdadero» número de componentes, afecta solo la complejidad algorítmica, no el número real de componentes usados).