Nota
Haz clic aquí para descargar el código completo del ejemplo o para ejecutar este ejemplo en tu navegador a través de Binder
Covarianzas GMM¶
Demostración de varios tipos de covarianzas para modelos de mezcla Gaussiana.
Consulta Modelos de mezclas gaussianas para obtener más información sobre el estimador.
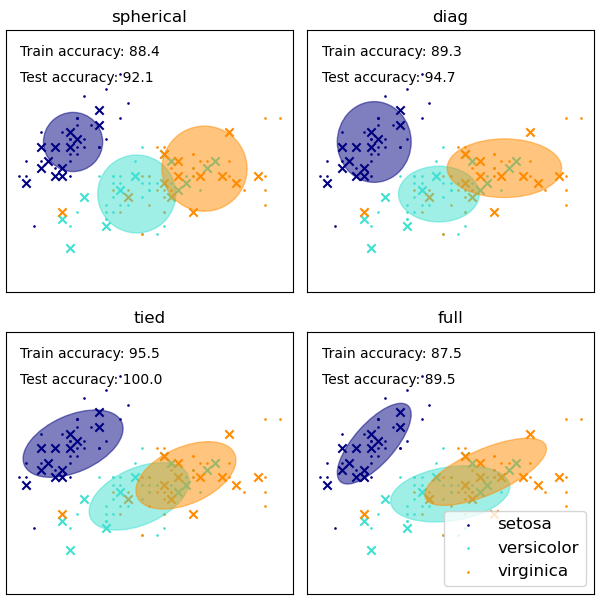
Aunque las GMM se utilizan a menudo para el agrupamiento, podemos comparar los conglomerados obtenidos con las clases reales del conjunto de datos. Inicializamos las medias de las Gaussianas con las medias de las clases del conjunto de entrenamiento para que esta comparación sea válida.
Graficamos las etiquetas predichas tanto en los datos de entrenamiento como en los datos de prueba retenidos utilizando una variedad de tipos de covarianza GMM en el conjunto de datos iris. Comparamos los GMM con matrices de covarianza esféricas, diagonales, completas y ligadas en orden creciente de rendimiento. Aunque cabría esperar que la covarianza completa tuviera el mejor rendimiento en general, es propensa a sobreajustarse en conjuntos de datos pequeños y no se generaliza bien a los datos de prueba retenidos.
En los gráficos, los datos de entrenamiento se muestran como puntos, mientras que los datos de prueba se muestran como cruces. El conjunto de datos iris tiene cuatro dimensiones. Aquí sólo se muestran las dos primeras dimensiones, por lo que algunos puntos están separados en otras dimensiones.
# Author: Ron Weiss <ronweiss@gmail.com>, Gael Varoquaux
# Modified by Thierry Guillemot <thierry.guillemot.work@gmail.com>
# License: BSD 3 clause
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.mixture import GaussianMixture
from sklearn.model_selection import StratifiedKFold
print(__doc__)
colors = ['navy', 'turquoise', 'darkorange']
def make_ellipses(gmm, ax):
for n, color in enumerate(colors):
if gmm.covariance_type == 'full':
covariances = gmm.covariances_[n][:2, :2]
elif gmm.covariance_type == 'tied':
covariances = gmm.covariances_[:2, :2]
elif gmm.covariance_type == 'diag':
covariances = np.diag(gmm.covariances_[n][:2])
elif gmm.covariance_type == 'spherical':
covariances = np.eye(gmm.means_.shape[1]) * gmm.covariances_[n]
v, w = np.linalg.eigh(covariances)
u = w[0] / np.linalg.norm(w[0])
angle = np.arctan2(u[1], u[0])
angle = 180 * angle / np.pi # convert to degrees
v = 2. * np.sqrt(2.) * np.sqrt(v)
ell = mpl.patches.Ellipse(gmm.means_[n, :2], v[0], v[1],
180 + angle, color=color)
ell.set_clip_box(ax.bbox)
ell.set_alpha(0.5)
ax.add_artist(ell)
ax.set_aspect('equal', 'datalim')
iris = datasets.load_iris()
# Break up the dataset into non-overlapping training (75%) and testing
# (25%) sets.
skf = StratifiedKFold(n_splits=4)
# Only take the first fold.
train_index, test_index = next(iter(skf.split(iris.data, iris.target)))
X_train = iris.data[train_index]
y_train = iris.target[train_index]
X_test = iris.data[test_index]
y_test = iris.target[test_index]
n_classes = len(np.unique(y_train))
# Try GMMs using different types of covariances.
estimators = {cov_type: GaussianMixture(n_components=n_classes,
covariance_type=cov_type, max_iter=20, random_state=0)
for cov_type in ['spherical', 'diag', 'tied', 'full']}
n_estimators = len(estimators)
plt.figure(figsize=(3 * n_estimators // 2, 6))
plt.subplots_adjust(bottom=.01, top=0.95, hspace=.15, wspace=.05,
left=.01, right=.99)
for index, (name, estimator) in enumerate(estimators.items()):
# Since we have class labels for the training data, we can
# initialize the GMM parameters in a supervised manner.
estimator.means_init = np.array([X_train[y_train == i].mean(axis=0)
for i in range(n_classes)])
# Train the other parameters using the EM algorithm.
estimator.fit(X_train)
h = plt.subplot(2, n_estimators // 2, index + 1)
make_ellipses(estimator, h)
for n, color in enumerate(colors):
data = iris.data[iris.target == n]
plt.scatter(data[:, 0], data[:, 1], s=0.8, color=color,
label=iris.target_names[n])
# Plot the test data with crosses
for n, color in enumerate(colors):
data = X_test[y_test == n]
plt.scatter(data[:, 0], data[:, 1], marker='x', color=color)
y_train_pred = estimator.predict(X_train)
train_accuracy = np.mean(y_train_pred.ravel() == y_train.ravel()) * 100
plt.text(0.05, 0.9, 'Train accuracy: %.1f' % train_accuracy,
transform=h.transAxes)
y_test_pred = estimator.predict(X_test)
test_accuracy = np.mean(y_test_pred.ravel() == y_test.ravel()) * 100
plt.text(0.05, 0.8, 'Test accuracy: %.1f' % test_accuracy,
transform=h.transAxes)
plt.xticks(())
plt.yticks(())
plt.title(name)
plt.legend(scatterpoints=1, loc='lower right', prop=dict(size=12))
plt.show()
Tiempo total de ejecución del script: (0 minutos 0.401 segundos)