1.14. Aprendizaje semi supervisado¶
El aprendizaje semi supervisado es una situación en la que en los datos de entrenamiento algunas de las muestras no están etiquetadas. Los estimadores semi supervisados en sklearn.semi_supervised son capaces de hacer uso de estos datos adicionales no etiquetados para capturar mejor la forma de la distribución de datos subyacente y generalizar mejor a las nuevas muestras. Estos algoritmos pueden funcionar bien cuando tenemos una cantidad muy pequeña de puntos etiquetados y una gran cantidad de puntos no etiquetados.
Entradas sin etiquetar en y
Es importante asignar un identificador a los puntos no etiquetados junto con los datos etiquetados cuando se entrena el modelo con el método fit. El identificador que utiliza esta implementación es el valor entero \(-1\). Ten en cuenta que para las etiquetas de cadena, el dtype de y debe ser object para que pueda contener tanto cadenas como enteros.
Nota
Los algoritmos semi supervisados necesitan hacer suposiciones sobre la distribución del conjunto de datos para lograr ganancias de rendimiento. Véase aquí para más detalles.
1.14.1. Auto entrenamiento¶
Esta implementación de auto entrenamiento se basa en el algoritmo de Yarowsky 1. Usando este algoritmo, un determinado clasificador supervisado puede funcionar como un clasificador semi supervisado, permitiéndole aprender de datos no etiquetados.
SelfTrainingClassifier puede ser llamado con cualquier clasificador que implemente predict_proba, pasado como parámetro base_classifier. En cada iteración, el base_classifier predice etiquetas para las muestras no etiquetadas y añade un subconjunto de estas etiquetas al conjunto de datos etiquetados.
La elección de este subconjunto está determinada por el criterio de selección. Esta selección se puede hacer utilizando un threshold en las probabilidades de predicción, o eligiendo las k_best muestras de acuerdo con las probabilidades de predicción.
Las etiquetas utilizadas para el ajuste final, así como la iteración en la que cada muestra fue etiquetada están disponibles como atributos. El parámetro opcional max_iter especifica cuántas veces se ejecuta el bucle como máximo.
El parámetro max_iter puede establecerse en None, haciendo iterar el algoritmo hasta que todas las muestras tengan etiquetas o no se seleccionen nuevas muestras en esa iteración.
Nota
Cuando se utiliza el clasificador de auto entrenamiento, la calibración del clasificador es importante.
Ejemplos
Referencias
- 1
David Yarowsky. 1995. Unsupervised word sense disambiguation rivaling supervised methods. In Proceedings of the 33rd annual meeting on Association for Computational Linguistics (ACL “95). Association for Computational Linguistics, Stroudsburg, PA, USA, 189-196. DOI: https://doi.org/10.3115/981658.981684
1.14.2. Propagación de etiquetas¶
La propagación de etiquetas denota algunas variaciones de los algoritmos de inferencia de grafos semi supervisados.
- Algunas características disponibles en este modelo:
Utilizado para tareas de clasificación
Métodos Kernel para proyectar datos en espacios dimensionales alternativos
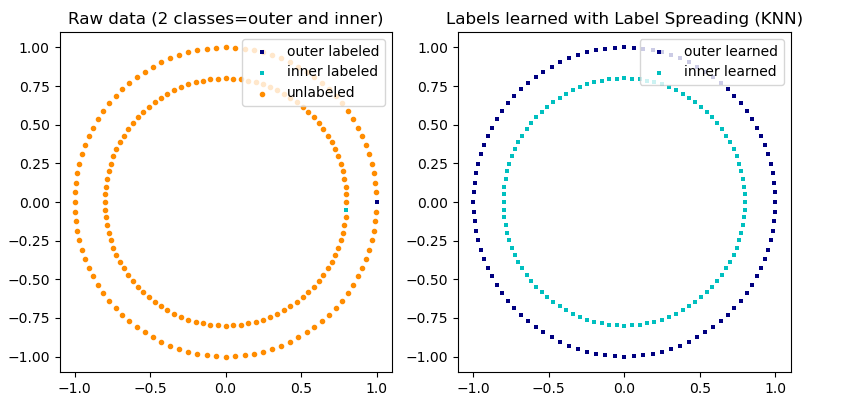
scikit-learn proporciona dos modelos de propagación de etiquetas: LabelPropagation y LabelSpreading. Ambos trabajan construyendo una gráfica de similitud sobre todos los elementos en el conjunto de datos de entrada.
Una ilustración de la propagación de etiquetas: la estructura de observaciones sin etiquetar es coherente con la estructura de la clase, y por lo tanto la etiqueta de la clase puede propagarse a las observaciones sin etiquetar del conjunto de entrenamiento.¶
LabelPropagation y LabelSpreading difieren en las modificaciones de la matriz de similitud que grafican y la restricción en las distribuciones de etiquetas. La restricción permite que el algoritmo cambie el peso de los datos etiquetados reales en cierto grado. El algoritmo LabelPropagation realiza una restricción dura de las etiquetas de entrada, lo que significa \(\alpha=0\). Este factor de restricción puede ser relajado, por ejemplo \(\alpha=0.2\), lo que significa que siempre mantendremos el 80 por ciento de nuestra distribución de etiquetas original, pero el algoritmo puede cambiar su confianza en la distribución dentro del 20 por ciento.
LabelPropagation utiliza la matriz de similitud en bruto construida a partir de los datos sin modificaciones. En cambio, LabelSpreading minimiza una función de pérdida que tiene propiedades de regularización, por lo que a menudo es más robusto al ruido. El algoritmo itera sobre una versión modificada del gráfico original y normaliza los pesos de las aristas calculando la matriz Laplaciana normalizada del gráfico. Este procedimiento también se utiliza en Análisis espectral de conglomerados.
Los modelos de propagación de etiquetas tienen dos métodos de kernel integrados. La elección del kernel afecta tanto la escalabilidad como el rendimiento de los algoritmos. Están disponibles los siguientes:
rbf (\(\exp(-\gamma |x-y|^2), \gamma > 0\)). \(\gamma\) se especifica con la palabra clave gamma.
knn (\(1[x' \in kNN(x)]\)). \(k\) se especifica con la palabra clave n_neighbors.
El núcleo RBF producirá un gráfico completamente conectado que está representado en memoria por una matriz densa. Esta matriz puede ser muy grande y, combinada con el costo de realizar un cálculo completo de multiplicación de la matriz para cada iteración del algoritmo, puede llevar a tiempos de ejecución prohibitivamente largos. Por otro lado, el núcleo KNN producirá una matriz dispersa mucho más amigable con la memoria que puede reducir drásticamente los tiempos de ejecución.
Ejemplos
Referencias
[2] Yoshua Bengio, Olivier Delalleau, Nicolas Le Roux. In Semi-Supervised Learning (2006), pp. 193-216
[3] Olivier Delalleau, Yoshua Bengio, Nicolas Le Roux. Efficient Non-Parametric Function Induction in Semi-Supervised Learning. AISTAT 2005 https://research.microsoft.com/en-us/people/nicolasl/efficient_ssl.pdf