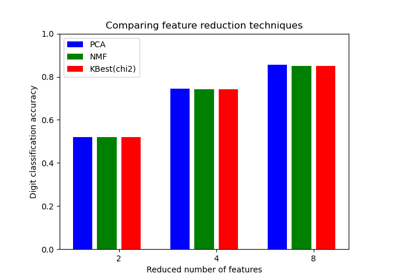
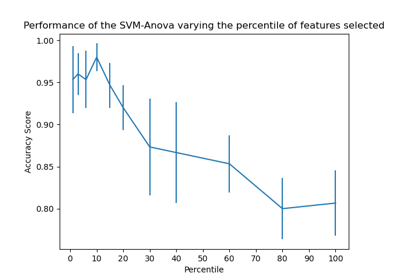
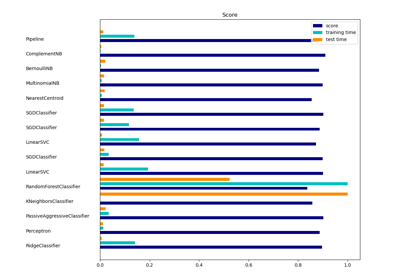
sklearn.feature_selection.chi2¶
- sklearn.feature_selection.chi2()¶
Calcula los estadísticos chi-cuadrado entre cada característica no negativa y la clase.
Esta puntuación puede utilizarse para seleccionar las n_features características con los valores más altos para el estadístico de prueba chi-cuadrado de X, que debe contener sólo características no negativas como booleanos o frecuencias (por ejemplo, recuentos de términos en la clasificación de documentos), en relación con las clases.
Recuerda que la prueba chi-cuadrado mide la dependencia entre las variables estocásticas, por lo que el uso de esta función «elimina» las características que tienen más probabilidad de ser independientes de la clase y, por tanto, irrelevantes para la clasificación.
Lee más en el Manual de usuario.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Vectores de muestra.
- yarray-like de forma (n_samples,)
Vector objetivo (etiquetas de clase).
- Devuelve
- chi2arreglo, forma = (n_features,)
Estadístico chi-cuadrado de cada característica.
- pvalarreglo, forma = (n_features,)
Los valores p de cada característica.
Ver también
f_classifValor-F de ANOVA entre etiqueta/característica para las tareas de clasificación.
f_regressionValor-F entre etiqueta/característica para tareas de regresión.
Notas
La complejidad de este algoritmo es O(n_classes * n_features).