sklearn.feature_selection.f_regression¶
- sklearn.feature_selection.f_regression()¶
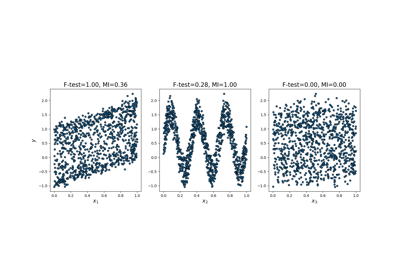
Pruebas de regresión lineal univariante.
Modelo lineal para probar el efecto individual de cada uno de los muchos regresores. Esta es una función de puntuación para ser utilizada en un procedimiento de selección de características, no un procedimiento de selección de características autónomo.
Esto se hace en 2 pasos:
Se calcula la correlación entre cada regresor y el objetivo, es decir, (X[:, i] - mean(X[:, i])) * (y - mean_y)) / (std(X[:, i]) * std(y)).
Se convierte a una puntuación F y luego a un valor-p.
Más información en el Manual de usuario.
- Parámetros
- X{array-like, sparse matrix} forma = (n_samples, n_features)
El conjunto de regresores que se probarán secuencialmente.
- yarreglo de forma(n_samples).
La matriz de datos
- centerbool, default=True
Si es verdadero, X e Y se centrarán.
- Devuelve
- Farreglo, forma=(n_features,)
Valores F de las características.
- pvalarreglo, forma=(n_features,)
valores-p de las puntuaciones-F.
Ver también
mutual_info_regressionInformación mutua para un objetivo continuo.
f_classifValor-F de ANOVA entre etiqueta/característica para tareas de clasificación.
chi2Estadísticas Chi-cuadrado de las características no negativas para las tareas de clasificación.
SelectKBestSelecciona características basándose en las k puntuaciones más altas.
SelectFprSelecciona características basándose en una prueba de tasa de falsos positivos.
SelectFdrSelecciona características basándose en una tasa estimada de falsos descubrimientos.
SelectFweSelecciona características en función de la tasa de error por familias.
SelectPercentileSelecciona características de acuerdo a un percentil de las puntuaciones más altas.