Nota
Haz clic aquí para descargar el código de ejemplo completo o para ejecutar este ejemplo en tu navegador a través de Binder
SVM-Anova: SVM con selección de características univariantes¶
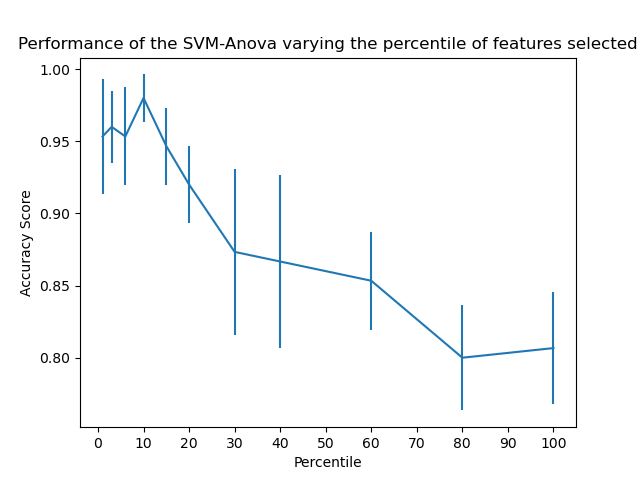
Este ejemplo muestra cómo realizar una selección de características univariantes antes de ejecutar un clasificador de vectores de soporte (SVC) para mejorar las puntuaciones de clasificación. Utilizamos el conjunto de datos del iris (4 características) y añadimos 36 características no informativas. Podemos comprobar que nuestro modelo alcanza el mejor rendimiento cuando seleccionamos alrededor del 10% de las características.
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectPercentile, chi2
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# #############################################################################
# Import some data to play with
X, y = load_iris(return_X_y=True)
# Add non-informative features
np.random.seed(0)
X = np.hstack((X, 2 * np.random.random((X.shape[0], 36))))
# #############################################################################
# Create a feature-selection transform, a scaler and an instance of SVM that we
# combine together to have an full-blown estimator
clf = Pipeline([('anova', SelectPercentile(chi2)),
('scaler', StandardScaler()),
('svc', SVC(gamma="auto"))])
# #############################################################################
# Plot the cross-validation score as a function of percentile of features
score_means = list()
score_stds = list()
percentiles = (1, 3, 6, 10, 15, 20, 30, 40, 60, 80, 100)
for percentile in percentiles:
clf.set_params(anova__percentile=percentile)
this_scores = cross_val_score(clf, X, y)
score_means.append(this_scores.mean())
score_stds.append(this_scores.std())
plt.errorbar(percentiles, score_means, np.array(score_stds))
plt.title(
'Performance of the SVM-Anova varying the percentile of features selected')
plt.xticks(np.linspace(0, 100, 11, endpoint=True))
plt.xlabel('Percentile')
plt.ylabel('Accuracy Score')
plt.axis('tight')
plt.show()
Tiempo total de ejecución del script: (0 minutos 0.330 segundos)