7.3. Conjuntos de datos generados¶
Además, scikit-learn incluye varios generadores de muestras aleatorias que pueden utilizarse para construir conjuntos de datos artificiales de tamaño y complejidad controlados.
7.3.1. Generadores para clasificación y análisis de conglomerados¶
Estos generadores producen una matriz de características y los correspondientes objetivos discretos.
7.3.1.1. Etiqueta única¶
Tanto make_blobs como make_classification crean conjuntos de datos multiclase asignando a cada clase uno o más conglomerados de puntos distribuidos normalmente. make_blobs proporciona un mayor control sobre los centros y las desviaciones estándar de cada conglomerado, y se utiliza para demostrar el análisis de conglomerados. make_classification se especializa en la introducción de ruido mediante: características correlacionadas, redundantes y no informativas; múltiples conglomerados Gaussianos por clase; y transformaciones lineales del espacio de características.
make_gaussian_quantiles divide un único conglomerado Gaussiano en clases de tamaño casi igual separadas por hiperesferas concéntricas. make_hastie_10_2 genera un problema binario similar de 10 dimensiones.
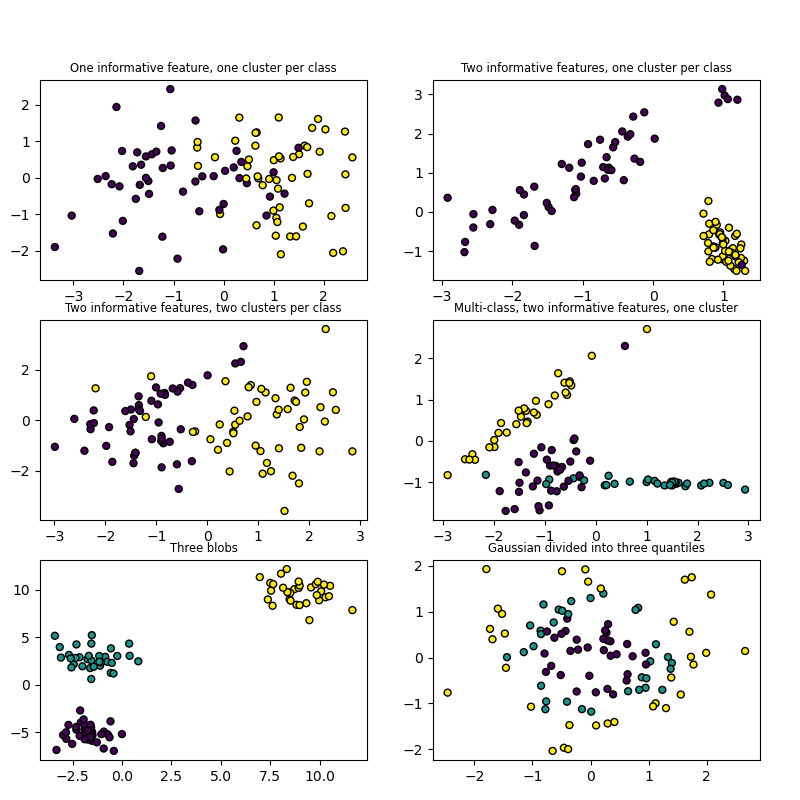
make_circles y make_moons generan conjuntos de datos de clasificación binaria 2D que suponen un reto para ciertos algoritmos (por ejemplo, el análisis de conglomerados basado en el centroide o la clasificación lineal), incluyendo ruido Gaussiano opcional. Son útiles para la visualización. make_circles produce datos Gaussianos con una frontera de decisión esférica para la clasificación binaria, mientras que make_moons produce dos medios círculos intercalados.
7.3.1.2. Multietiqueta¶
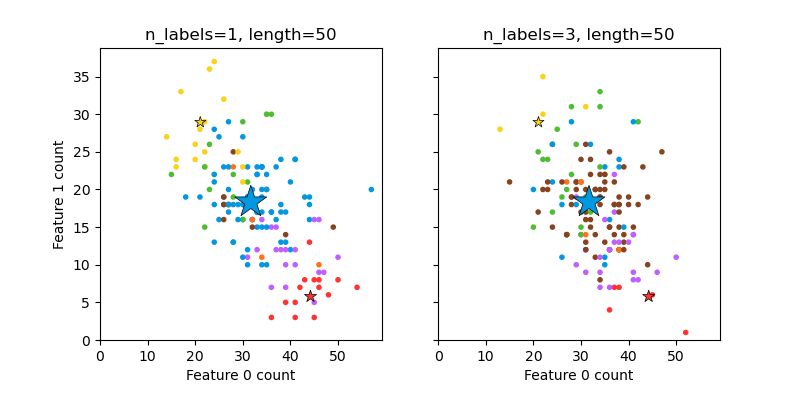
make_multilabel_classification genera muestras aleatorias con múltiples etiquetas, reflejando una bolsa de palabras (bag of words) extraídas de una mezcla de temas. El número de temas de cada documento se extrae de una distribución de Poisson, y los propios temas se extraen de una distribución aleatoria fija. Del mismo modo, el número de palabras se extrae de una Poisson, con palabras extraídas de una multinomial, donde cada tema define una distribución de probabilidad sobre las palabras. Las simplificaciones con respecto a las verdaderas mezclas de bolsas de palabras incluyen:
Las distribuciones de palabras por tema se dibujan de forma independiente, cuando en realidad todas estarían afectadas por una distribución de base dispersa, y estarían correlacionadas.
Para un documento generado a partir de múltiples temas, todos los temas se ponderan por igual al generar su bolsa de palabras (bag of words).
Documenta sin etiquetas palabras al azar, en lugar de desde una distribución base.
7.3.1.3. Biclustering¶
|
Genera un arreglo con estructura diagonal de bloque constante para el biclustering. |
|
Genera un arreglo con estructura de tablero de bloques para el biclustering. |
7.3.2. Generadores para regresión¶
make_regression produce objetivos de regresión como una combinación lineal aleatoria opcionalmente dispersa de características aleatorias, con ruido. Sus características informativas pueden no estar correlacionadas, o ser de bajo rango (pocas características representan la mayor parte de la varianza).
Otros generadores de regresión generan funciones de forma determinista a partir de características aleatorias. make_sparse_uncorrelated produce un objetivo como una combinación lineal de cuatro características con coeficientes fijos. Otros codifican explícitamente relaciones no lineales: make_friedman1 se relaciona mediante transformaciones polinomiales y sinusoidales; make_friedman2 incluye la multiplicación de características y la reciprocidad; y make_friedman3 es similar con una transformación arcotangente en el objetivo.
7.3.3. Generadores para aprendizaje múltiple¶
|
Genera un conjunto de datos de la curva S. |
|
Genera un conjunto de datos de rollo suizo (swiss roll). |
7.3.4. Generadores para descomposición¶
|
Genera una matriz de rango mayoritariamente bajo con valores singulares en forma de campana. |
|
Genera una señal como una combinación dispersa de elementos del diccionario. |
|
Genera una matriz aleatoria simétrica y definida positiva. |
|
Genera una matriz dispersa simétrica definida positiva. |