8.1. Estrategias para escalar computacionalmente: datos más grandes¶
Para algunas aplicaciones, la cantidad de ejemplos, características (o ambas) y/o la velocidad a la que necesitan ser procesadas son un reto para los enfoques tradicionales. En estos casos, scikit-learn tiene una serie de opciones que puede considerar para hacer que tu sistema sea escalable.
8.1.1. Escalar con instancias utilizando el aprendizaje fuera del núcleo¶
El aprendizaje fuera del núcleo (o «memoria externa») es una técnica utilizada para aprender de los datos que no caben en la memoria principal (RAM) de una computadora.
He aquí un esbozo de un sistema diseñado para lograr este objetivo:
una forma de transmitir instancias
una forma de extraer características de las instancias
un algoritmo incremental
8.1.1.1. Instancias de streaming¶
Básicamente, 1. puede ser un lector que obtenga instancias de archivos en un disco duro, una base de datos, de un flujo de red, etc. Sin embargo, los detalles sobre cómo lograr esto están más allá del alcance de esta documentación.
8.1.1.2. Extracción de características¶
2. podría ser cualquier forma relevante de extraer características entre los diferentes métodos de extracción de características soportados por scikit-learn. Sin embargo, cuando se trabaja con datos que necesitan vectorización y donde el conjunto de características o valores no se conoce de antemano se debe tener un cuidado explícito. Un buen ejemplo es la clasificación de textos donde es probable que se encuentren términos desconocidos durante el entrenamiento. Es posible utilizar un vectorizador con estado si hacer varias pasadas sobre los datos es razonable desde el punto de vista de la aplicación. De lo contrario, se puede aumentar la dificultad utilizando un extractor de características sin estado. Actualmente la forma preferida de hacer esto es utilizar el llamado truco hashing como el implementado por sklearn.feature_extraction.FeatureHasher para conjuntos de datos con variables categóricas representadas como lista de diccionarios (dicts) de Python o sklearn.feature_extraction.text.HashingVectorizer para documentos de texto.
8.1.1.3. Aprendizaje incremental¶
Finalmente, para la 3. tenemos una serie de opciones dentro de scikit-learn. Aunque no todos los algoritmos pueden aprender de forma incremental (es decir, sin ver todas las instancias a la vez), todos los estimadores que implementan la API partial_fit son candidatos. En realidad, la capacidad de aprender de forma incremental a partir de un minilote de instancias (a veces llamado «aprendizaje en línea») es clave para el aprendizaje fuera del núcleo, ya que garantiza que en cualquier momento sólo habrá una pequeña cantidad de instancias en la memoria principal. La elección de un buen tamaño para el mini lote que equilibre la relevancia y la huella de memoria podría implicar algunos ajustes 1.
A continuación se presenta una lista de estimadores incrementales para diferentes tareas:
- Análisis de conglomerados
- Descomposición/extracción de características
Para la clasificación, una cosa importante a tener en cuenta es que aunque una rutina de extracción de características sin estado puede ser capaz de hacer frente a los atributos nuevos/no vistos, el propio aprendiz incremental puede ser incapaz de hacer frente a las clases objetivo nuevas/no vistas. En este caso hay que pasar todas las clases posibles a la primera llamada de partial_fit utilizando el parámetro classes=.
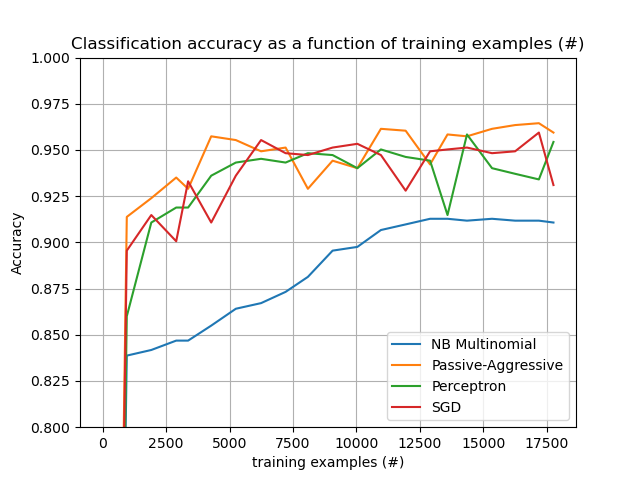
Otro aspecto a tener en cuenta a la hora de elegir un algoritmo adecuado es que no todos dan la misma importancia a cada ejemplo a lo largo del tiempo. En concreto, el Perceptron sigue siendo sensible a los ejemplos mal etiquetados incluso después de muchos ejemplos, mientras que las familias SGD* y PassiveAggressive* son más robustas a este tipo de artefactos. A la inversa, estos últimos también tienden a dar menos importancia a los ejemplos notablemente diferentes, aunque correctamente etiquetados, cuando llegan tarde en el flujo, ya que su tasa de aprendizaje disminuye con el tiempo.
8.1.1.4. Ejemplos¶
Por último, tenemos un ejemplo completo de Clasificación de documentos de texto fuera del núcleo. Su objetivo es proporcionar un punto de partida para las personas que quieren construir sistemas de aprendizaje fuera del núcleo y demuestra la mayoría de las nociones discutidas anteriormente.
Además, también muestra la evolución del rendimiento de los distintos algoritmos con el número de ejemplos procesados.
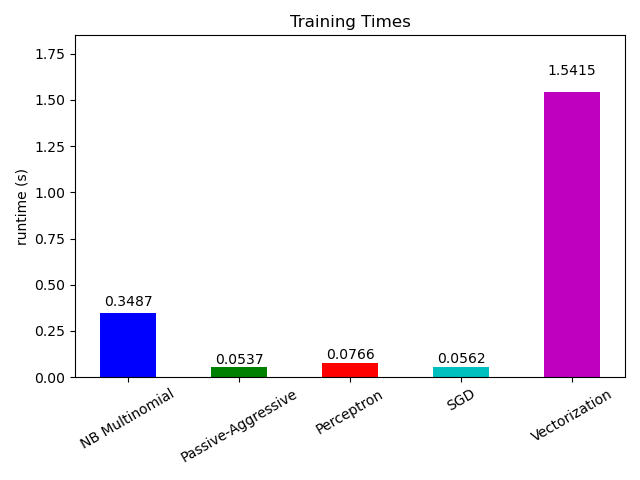
Si observamos el tiempo de cálculo de las diferentes partes, vemos que la vectorización es mucho más cara que el aprendizaje en sí. De los diferentes algoritmos, MultinomialNB es el más caro, pero su sobrecarga se puede mitigar aumentando el tamaño de los mini-lotes (ejercicio: cambiar minibatch_size a 100 y 10000 en el programa y comparar).
8.1.1.5. Notas¶
- 1
Dependiendo del algoritmo, el tamaño del mini lote puede influir en los resultados o no. SGD*, PassiveAggressive* y NaiveBayes discreto son realmente online y no se ven afectados por el tamaño del lote. Por el contrario, la tasa de convergencia de MiniBatchKMeans se ve afectada por el tamaño del lote. Además, su consumo de memoria puede variar drásticamente con el tamaño del lote.