8.2. Rendimiento computacional¶
Para algunas aplicaciones, el rendimiento (principalmente la latencia y el rendimiento en el momento de la predicción) de los estimadores es crucial. También puede ser interesante tener en cuenta el rendimiento del entrenamiento, pero esto suele ser menos importante en una configuración de producción (donde a menudo tiene lugar fuera de línea).
Revisaremos aquí los órdenes de magnitud que se pueden esperar de una serie de estimadores de scikit-learn en diferentes contextos y proporcionaremos algunos consejos y trucos para superar los cuellos de botella de rendimiento.
La latencia de predicción se mide como el tiempo necesario para realizar una predicción (por ejemplo, en microsegundos). La latencia suele verse como una distribución y los ingenieros de operaciones suelen centrarse en la latencia en un percentil determinado de esta distribución (por ejemplo, el percentil 90).
El rendimiento de las predicciones se define como el número de predicciones que el software puede realizar en un tiempo determinado (por ejemplo, en predicciones por segundo).
Un aspecto importante de la optimización del rendimiento es también que puede perjudicar la precisión de las predicciones. En efecto, los modelos más sencillos (por ejemplo, lineales en lugar de no lineales, o con menos parámetros) suelen funcionar más rápido, pero no siempre son capaces de tener en cuenta las mismas propiedades exactas de los datos que los más complejos.
8.2.1. Latencia de predicción¶
Una de las preocupaciones más directas que uno puede tener al utilizar/elegir un conjunto de herramientas de aprendizaje automático es la latencia con la que se pueden hacer predicciones en un entorno de producción.
- Los principales factores que influyen en la latencia de la predicción son
Número de características
Representación de los datos de entrada y dispersión
Complejidad del modelo
Extracción de características
Un último parámetro importante es también la posibilidad de hacer predicciones en modo masivo o uno a uno.
8.2.1.1. Modo Bulk versus Atómico¶
En general, hacer predicciones a granel (muchas instancias al mismo tiempo) es más eficiente por una serie de razones (previsibilidad de bifurcación, caché de la CPU, optimizaciones de las bibliotecas de álgebra lineal, etc.). Aquí vemos, en un entorno con pocas características, que, independientemente de la elección del estimador, el modo masivo es siempre más rápido, y para algunos de ellos en 1 o 2 órdenes de magnitud:
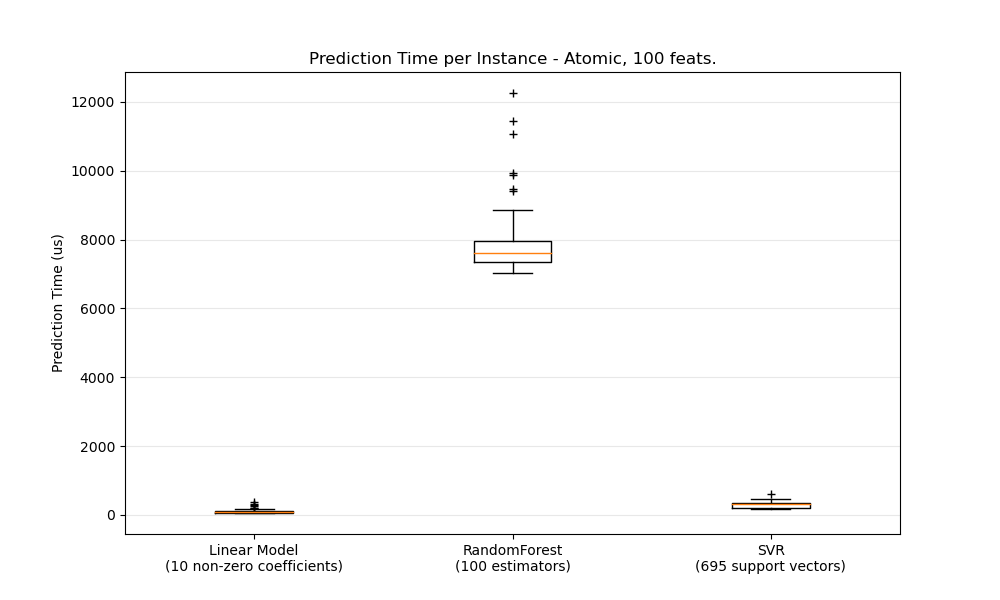
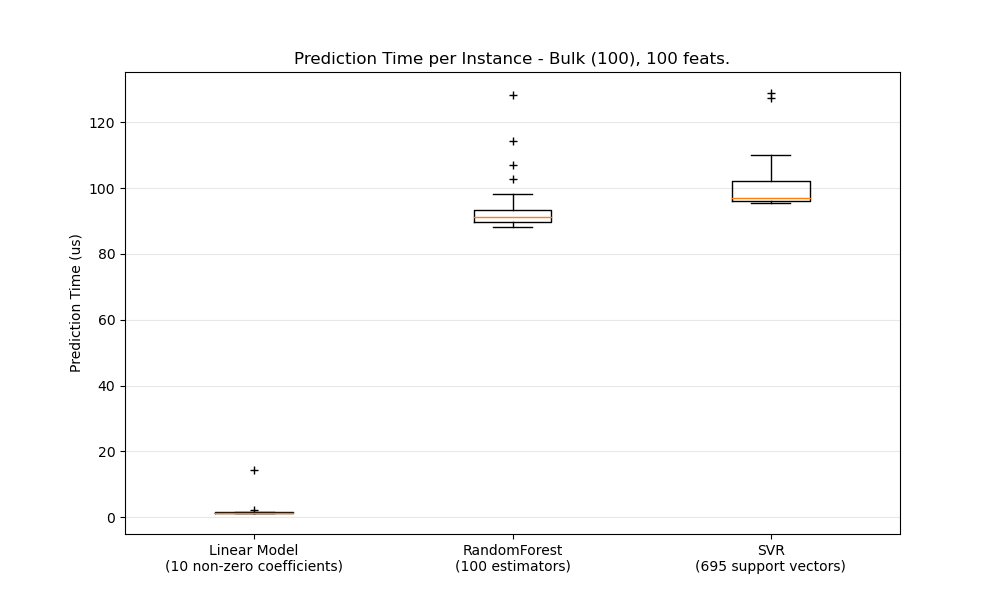
Para comparar diferentes estimadores en su caso, sólo tienes que cambiar el parámetro n_features en este ejemplo: Latencia de predicción. Esto debería darte una estimación del orden de magnitud de la latencia de predicción.
8.2.1.2. Configuración de Scikit-learn para reducir la carga de validación¶
Scikit-learn realiza algunas validaciones sobre los datos que aumentan la sobrecarga por llamada a predict y funciones similares. En particular, la comprobación de que las características son finitas (no NaN o infinitas) implica una pasada completa por los datos. Si se asegura de que sus datos son aceptables, puede suprimir la comprobación de finitud estableciendo la variable de entorno SKLEARN_ASSUME_FINITE a una cadena no vacía antes de importar scikit-learn, o configurarlo en Python con set_config. Para un mayor control que estas configuraciones globales, un config_context te permite establecer esta configuración dentro de un contexto especificado:
>>> import sklearn
>>> with sklearn.config_context(assume_finite=True):
... pass # do learning/prediction here with reduced validation
Nota que esto afectará a todos los usos de assert_all_finite dentro del contexto.
8.2.1.3. Influencia del número de características¶
Obviamente, cuando el número de características aumenta, también lo hace el consumo de memoria de cada ejemplo. De hecho, para una matriz de \(M\) instancias con \(N\) características, la complejidad espacial está en \(O(NM)\). Desde el punto de vista informático, esto significa también que el número de operaciones básicas (por ejemplo, las multiplicaciones para los productos vector-matriz en los modelos lineales) también aumenta. He aquí un gráfico de la evolución de la latencia de la predicción con el número de características:
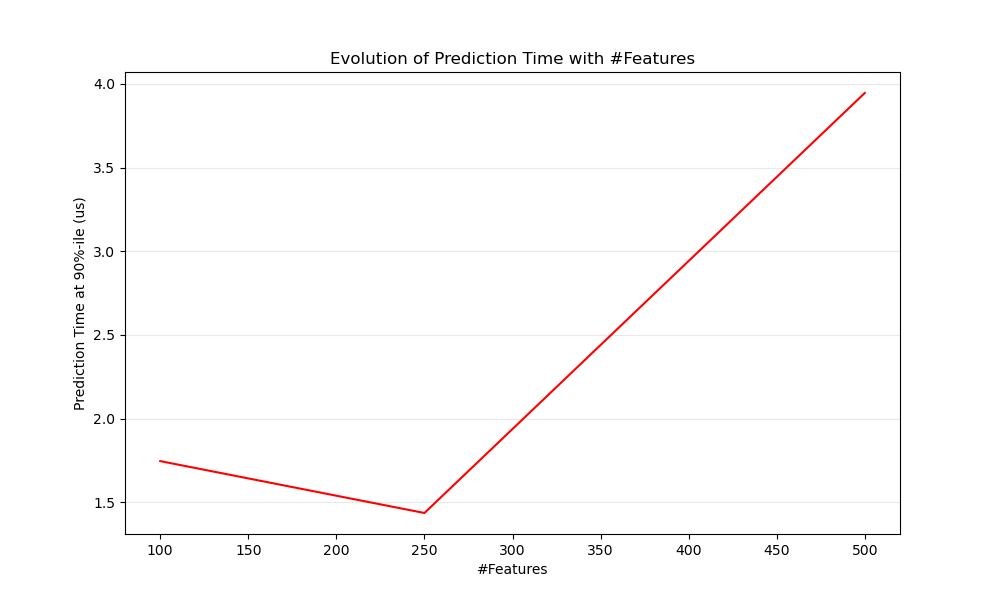
En general, se puede esperar que el tiempo de predicción aumente al menos linealmente con el número de características (pueden darse casos no lineales dependiendo de la huella de memoria global y del estimador).
8.2.1.4. Influencia de la representación de los datos de entrada¶
Scipy proporciona estructuras de datos de matrices dispersas que están optimizadas para almacenar datos dispersos. La principal característica de los formatos dispersos es que no se almacenan ceros, por lo que si los datos son dispersos, se utiliza mucha menos memoria. Un valor distinto de cero en una representación dispersa (CSR o CSC) sólo ocupará, por término medio, una posición entera de 32 bits + el valor de 64 bits en coma flotante + otros 32 bits por fila o columna de la matriz. El uso de una entrada dispersa en un modelo lineal denso (o disperso) puede acelerar la predicción en gran medida, ya que sólo las características de valor no nulo afectan al producto de puntos y, por tanto, a las predicciones del modelo. Por lo tanto, si tiene 100 valores no nulos en un espacio de 1e6 dimensiones, sólo necesitará 100 operaciones de multiplicación y suma en lugar de 1e6.
El cálculo sobre una representación densa, sin embargo, puede aprovechar las operaciones vectoriales altamente optimizadas y el multithreading en BLAS, y tiende a dar lugar a menos pérdidas de caché de la CPU. Por lo tanto, la dispersión debería ser bastante alta (10% de no ceros como máximo, a comprobar dependiendo del hardware) para que la representación de entrada dispersa sea más rápida que la representación de entrada densa en una máquina con muchas CPUs y una implementación de BLAS optimizada.
Aquí hay un código de ejemplo para probar la escasez de su entrada:
def sparsity_ratio(X):
return 1.0 - np.count_nonzero(X) / float(X.shape[0] * X.shape[1])
print("input sparsity ratio:", sparsity_ratio(X))
Como regla general, puedes considerar que si la tasa de dispersión es superior al 90%, probablemente puedas beneficiarte de los formatos dispersos. Consulta la documentación sobre formatos de matrices dispersas de Scipy para obtener más información sobre cómo construir (o convertir tus datos a) formatos de matrices dispersas. La mayoría de las veces los formatos CSR y CSC funcionan mejor.
8.2.1.5. Influencia de la complejidad del modelo¶
En general, cuando la complejidad del modelo aumenta, se supone que la potencia de predicción y la latencia aumentan. Aumentar la capacidad de predicción suele ser interesante, pero para muchas aplicaciones es mejor no aumentar demasiado la latencia de la predicción. A continuación revisaremos esta idea para diferentes familias de modelos supervisados.
Para sklearn.linear_model (por ejemplo, Lasso, ElasticNet, SGDClassifier/Regressor, Ridge & RidgeClassifier, PassiveAggressiveClassifier/Regressor, LinearSVC, LogisticRegression…) la función de decisión que se aplica en el momento de la predicción es la misma (un producto punto) , por lo que la latencia debería ser equivalente.
Aquí hay un ejemplo usando SGDClassifier con la penalización elasticnet. La fuerza de la regularización es controlada globalmente por el parámetro alpha. Con un parámetro «alfa» suficientemente alto, se puede aumentar el parámetro «l1_ratio» de «elasticnet» para imponer varios niveles de dispersión en los coeficientes del modelo. Una mayor dispersión se interpreta como una menor complejidad del modelo, ya que necesitamos menos coeficientes para describirlo completamente. Por supuesto, la dispersión influye a su vez en el tiempo de predicción, ya que el producto-punto disperso requiere un tiempo aproximadamente proporcional al número de coeficientes distintos de cero.
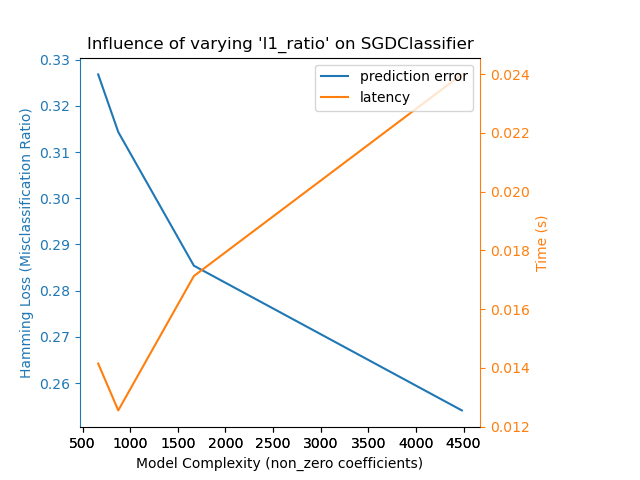
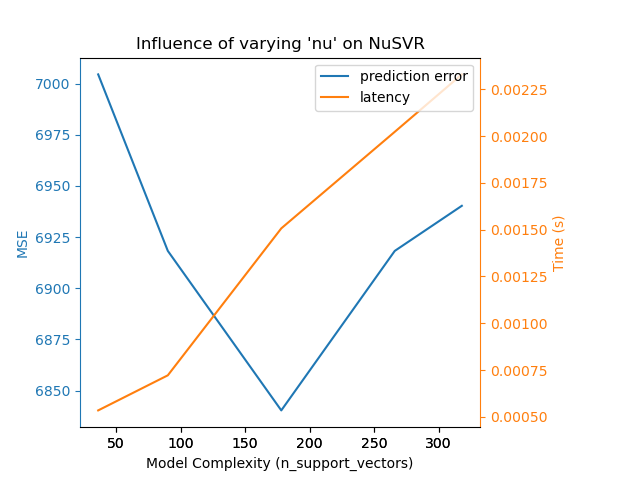
Para la familia de algoritmos sklearn.svm con un núcleo no lineal, la latencia está ligada al número de vectores de soporte (cuanto menos, más rápido). La latencia y el rendimiento deberían crecer (asintóticamente) de forma lineal con el número de vectores de soporte en un modelo SVC o SVR. El núcleo también influye en la latencia, ya que se utiliza para calcular la proyección del vector de entrada una vez por vector de soporte. En el siguiente gráfico se utilizó el parámetro nu de NuSVR para influir en el número de vectores de soporte.
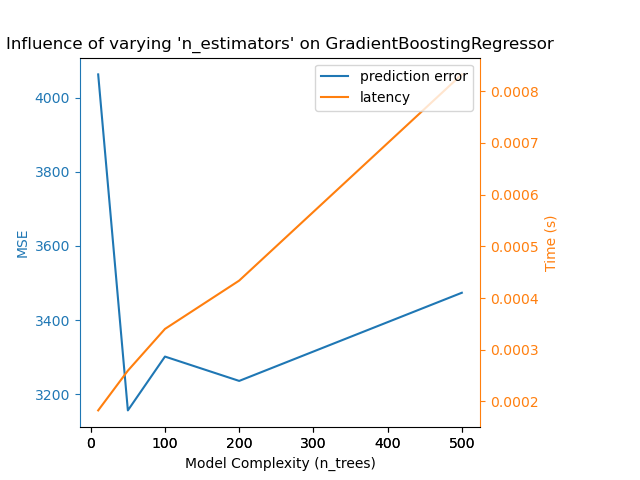
En el caso de sklearn.ensemble de árboles (por ejemplo, RandomForest, GBT, ExtraTrees, etc.), el número de árboles y su profundidad desempeñan el papel más importante. La latencia y el rendimiento deberían escalar linealmente con el número de árboles. En este caso utilizamos directamente el parámetro n_estimators de GradientBoostingRegressor.
En cualquier caso, hay que tener en cuenta que la disminución de la complejidad del modelo puede perjudicar la precisión, como se ha mencionado anteriormente. Por ejemplo, un problema separable de forma no lineal puede tratarse con un modelo lineal rápido, pero es muy probable que la capacidad de predicción se vea afectada en el proceso.
8.2.1.6. Latencia de la extracción de características¶
La mayoría de los modelos de scikit-learn suelen ser bastante rápidos, ya que se implementan con extensiones compiladas de Cython o bibliotecas de computación optimizadas. Por otro lado, en muchas aplicaciones del mundo real, el proceso de extracción de características (es decir, la conversión de los datos en bruto, como las filas de la base de datos o los paquetes de red, en arreglos de numpy) rige el tiempo de predicción general. Por ejemplo, en la tarea de clasificación de textos de Reuters, toda la preparación (lectura y análisis sintáctico de los archivos SGML, tokenización del texto y hash en un espacio vectorial común) lleva de 100 a 500 veces más tiempo que el código de predicción real, dependiendo del modelo elegido.
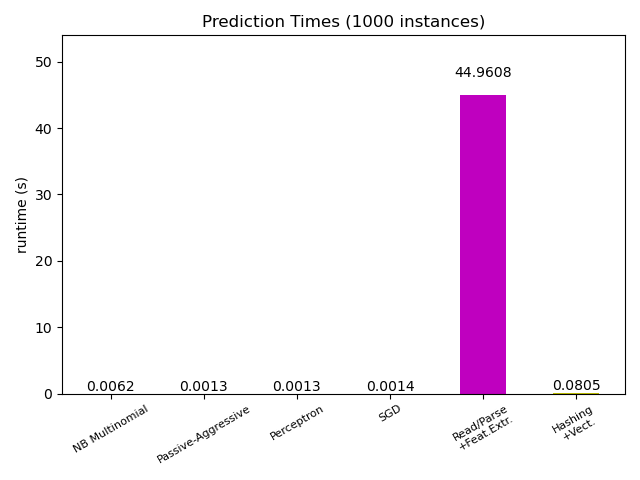
Por lo tanto, en muchos casos se recomienda cronometrar y perfilar cuidadosamente su código de extracción de características, ya que puede ser un buen lugar para comenzar a optimizar cuando su latencia general es demasiado lenta para su aplicación.
8.2.2. Rendimiento de predicción¶
Otra métrica importante que hay que tener en cuenta a la hora de dimensionar los sistemas de producción es el rendimiento, es decir, el número de predicciones que se pueden hacer en un tiempo determinado. A continuación se muestra una referencia del ejemplo Latencia de predicción que mide esta cantidad para una serie de estimadores sobre datos sintéticos:
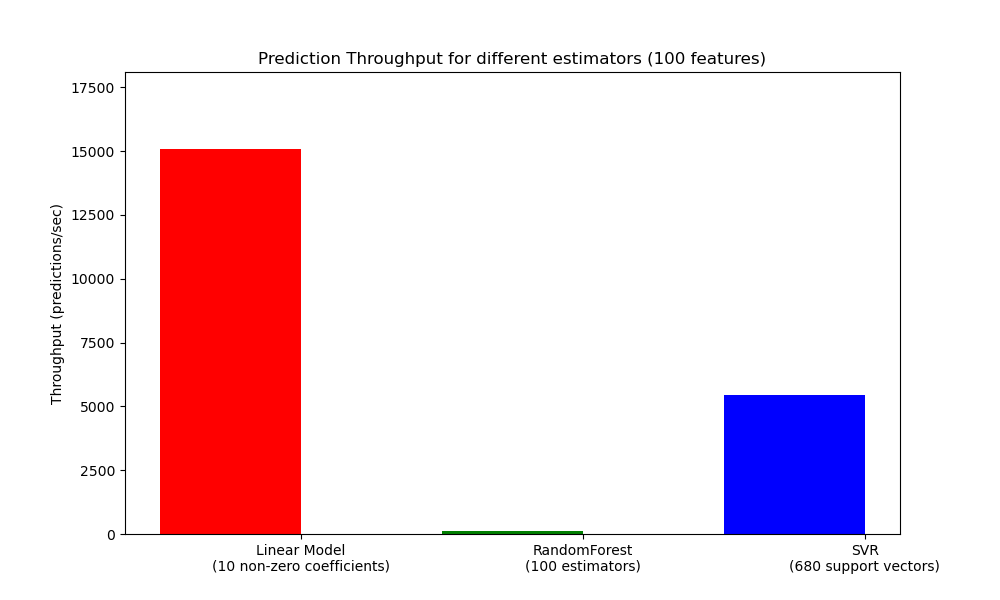
Estos rendimientos se consiguen en un solo proceso. Una forma obvia de aumentar el rendimiento de tu aplicación es generar instancias adicionales (normalmente procesos en Python debido al GIL) que compartan el mismo modelo. También se pueden añadir máquinas para repartir la carga. Sin embargo, una explicación detallada sobre cómo lograr esto está más allá del alcance de esta documentación.
8.2.3. Consejos y trucos¶
8.2.3.1. Bibliotecas de álgebra lineal¶
Como scikit-learn depende en gran medida de Numpy/Scipy y del álgebra lineal en general, tiene sentido cuidar explícitamente las versiones de estas bibliotecas. Básicamente, debe asegurarse de que Numpy se construye utilizando una biblioteca optimizada BLAS / LAPACK.
No todos los modelos se benefician de las implementaciones optimizadas de BLAS y Lapack. Por ejemplo, los modelos basados en árboles de decisión (aleatorios) no suelen depender de las llamadas a BLAS en sus bucles internos, ni tampoco los SVM de núcleo (SVC, SVR, NuSVC, NuSVR). Por otro lado, un modelo lineal implementado con una llamada BLAS DGEMM (a través de numpy.dot) se beneficiará enormemente de una implementación BLAS ajustada y conducirá a órdenes de magnitud de velocidad sobre un BLAS no optimizado.
Puede mostrar la implementación de BLAS / LAPACK utilizada por su instalación de NumPy / SciPy / scikit-learn con los siguientes comandos:
from numpy.distutils.system_info import get_info
print(get_info('blas_opt'))
print(get_info('lapack_opt'))
- Las implementaciones optimizadas de BLAS / LAPACK incluyen:
Atlas (necesita un ajuste específico del hardware mediante la reconstrucción en la máquina de destino)
OpenBLAS
MKL
Marcos Apple Accelerate y vecLib (sólo para OSX)
Se puede encontrar más información en la página de instalación de Scipy y en este blog post de Daniel Nouri que tiene algunas buenas instrucciones de instalación paso a paso para Debian / Ubuntu.
8.2.3.2. Limitación de la memoria de trabajo¶
Algunos cálculos cuando se implementan utilizando operaciones vectoriales estándar de numpy implican el uso de una gran cantidad de memoria temporal. Esto puede potencialmente agotar la memoria del sistema. Cuando los cálculos pueden realizarse en trozos de memoria fija, intentamos hacerlo, y permitimos al usuario indicar el tamaño máximo de esta memoria de trabajo (por defecto 1GB) usando set_config o config_context. Lo siguiente sugiere limitar la memoria de trabajo temporal a 128 MiB:
>>> import sklearn
>>> with sklearn.config_context(working_memory=128):
... pass # do chunked work here
Un ejemplo de operación fragmentada que se adhiere a esta configuración es pairwise_distances_chunked, que facilita el cálculo de las reducciones por filas de una matriz de distancia por pares.
8.2.3.3. Modelo de compresión¶
La compresión de modelos en scikit-learn sólo se refiere a los modelos lineales por el momento. En este contexto, significa que queremos controlar la dispersión del modelo (es decir, el número de coordenadas no nulas en los vectores del modelo). Por lo general, es una buena idea combinar la dispersión del modelo con la representación de datos de entrada dispersos.
Este es un ejemplo de código que ilustra el uso del método sparsify():
clf = SGDRegressor(penalty='elasticnet', l1_ratio=0.25)
clf.fit(X_train, y_train).sparsify()
clf.predict(X_test)
En este ejemplo preferimos la penalización elasticnet ya que suele ser un buen compromiso entre la compacidad del modelo y la potencia de predicción. También se puede ajustar el parámetro l1_ratio (en combinación con la fuerza de regularización alpha) para controlar este compromiso.
Una típica benchmark sobre datos sintéticos arroja una disminución de la latencia superior al 30% cuando tanto el modelo como la entrada son dispersos (con una proporción de coeficientes no nulos de 0.000024 y 0.027400 respectivamente). El kilometraje puede variar en función de la dispersión y el tamaño de los datos y el modelo. Además, la sparsificación puede ser muy útil para reducir el uso de memoria de los modelos predictivos desplegados en los servidores de producción.
8.2.3.4. Reestructuración de modelos¶
La reestructuración del modelo consiste en seleccionar sólo una parte de las características disponibles para ajustar un modelo. En otras palabras, si un modelo descarta características durante la fase de aprendizaje, podemos eliminarlas de la entrada. Esto tiene varias ventajas. En primer lugar, reduce la sobrecarga de memoria (y, por tanto, de tiempo) del propio modelo. También permite descartar componentes de selección de características explícitas en una cadena de producción una vez que sabemos qué características conservar de una ejecución anterior. Por último, puede ayudar a reducir el tiempo de procesamiento y el uso de E/S en las capas de acceso a los datos y de extracción de características al no recoger y construir características que son descartadas por el modelo. Por ejemplo, si los datos brutos proceden de una base de datos, puede permitir escribir consultas más sencillas y rápidas o reducir el uso de E/S haciendo que las consultas devuelvan registros más ligeros. Por el momento, la remodelación debe realizarse manualmente en scikit-learn. En el caso de entradas dispersas (particularmente en formato CSR), generalmente es suficiente con no generar las características relevantes, dejando sus columnas vacías.