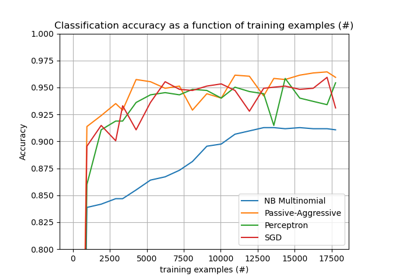
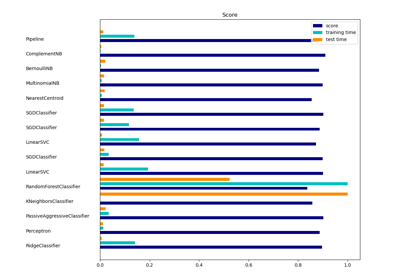
sklearn.feature_extraction.text.HashingVectorizer¶
- class sklearn.feature_extraction.text.HashingVectorizer¶
Convertir una colección de documentos de texto en una matriz de ocurrencias de tokens
Convierte una colección de documentos de texto en una matriz scipy.sparse que contiene conteos de ocurrencia de tokens (o información de ocurrencia binaria), posiblemente normalizada como frecuencias de tokens si norm=”l1” o proyectada en la esfera unitaria euclidiana si norm=”l2”.
Esta implementación del vectorizador de texto utiliza el truco del hashing para encontrar el nombre de la cadena del token para el mapeo de índices enteros de características.
Esta estrategia tiene varias ventajas:
es muy poco escalable en memoria para grandes conjuntos de datos, ya que no es necesario almacenar un diccionario de vocabulario en memoria
es rápido para hacer y deshacer el pickle ya que no mantiene ningún estado aparte de los parámetros del constructor
se puede utilizar en una transmisión (ajuste parcial) o en un pipeline paralelo, ya que no se calcula el estado durante el ajuste.
También hay un par de contras (en comparación con el uso de CountVectorizer con un vocabulario en memoria):
no hay forma de calcular la transformación inversa (desde los índices de características hasta los nombres de características de cadena), lo que puede ser un problema cuando se trata de introspeccionar qué características son más importantes para un modelo.
puede haber colisiones: tokens distintos pueden ser mapeados al mismo índice de características. Sin embargo, en la práctica, esto rara vez suele ser un problema si n_features es lo suficientemente grande (por ejemplo, 2 ** 18 para problemas de clasificación de texto).
sin ponderación de la IDF, ya que esto haría que el transformador tuviera estado.
La función hash empleada es la versión firmada de 32 bits de Murmurhash3.
Lee más en el Manual de usuario.
- Parámetros
- inputcadena de caracteres {“filename”, “file”, “content”}, default=”content”
Si es “filename”, se espera que la secuencia pasada como argumento a fit sea una lista de nombres de archivos que necesitan ser leídos para obtener el contenido en bruto a analizar.
Si es “file”, los elementos de la secuencia deben tener un método “read” de lectura (objeto file-like) que se invoca para obtener los bytes en la memoria.
En caso contrario, se espera que la entrada sea una secuencia de elementos que pueden ser de tipo cadena (string) o byte.
- encodingcadena de caracteres, default=”utf-8”
Si se dan bytes o archivos para analizar, se utiliza esta codificación para decodificar.
- decode_error{“strict”, “ignore”, “replace”}, default=”strict”
Instrucción sobre qué hacer si se proporciona una secuencia de bytes para analizar que contiene caracteres que no pertencen al
encoding(codificación) dado. Por defecto, es “strict”, lo que significa que se producirá un UnicodeDecodeError. Otros valores son “ignore” y “replace”.- strip_accents{“ascii”, “unicode”}, default=None
Elimina acentos y realiza otra normalización de caracteres durante el paso de preprocesamiento. “ascii” es un método rápido que sólo funciona sobre caracteres que tienen un mapeo ASCII directo. “unicode” es un método ligeramente más lento que funciona en cualquier carácter. None (predeterminado) no hace nada.
Tanto “ascii” como “unicode” utilizan la normalización NFKD de
unicodedata.normalize.- lowercasebool, default=True
Convierte todos los caracteres en minúsculas antes de la tokenización.
- preprocessorinvocable, default=None
Anula la etapa de preprocesamiento (transformación de cadenas) conservando las etapas de tokenización y generación de n-gramas. Sólo se aplica si
analyzerno es invocable.- tokenizerinvocable, default=None
Anula el paso de tokenización de cadenas conservando los pasos de preprocesamiento y generación de n-gramas. Sólo se aplica si
analyzer == 'word'.- stop_wordscadena de caracteres {“english”}, list, default=None
Si es “english”, se utiliza una lista de palabras funcionales incorporada para el inglés. Hay varias incidencias conocidas con “english” y deberías considerar una alternativa (ver Usando palabras funcionales (stop words)).
Si es una lista (list), se asume que dicha lista contiene palabras funcionales, las cuales serán eliminadas de los tokens resultantes. Sólo se aplica si
analyzer == 'word'.- token_pattern : cadena, default=r»(?u)\b\w\w+\b»str, default=r»(?u)\b\w\w+\b»
Expresión regular que denota lo que constituye un «token», sólo se utiliza si
analyzer == 'word'. La regexp predeterminada selecciona tokens de 2 o más caracteres alfanuméricos (la puntuación se ignora por completo y se trata siempre como un separador de tokens).Si hay un grupo de captura en token_pattern entonces el contenido del grupo capturado, no la correspondencia completa, se convierte en el token. Se permite como máximo un grupo de captura.
- ngram_rangetupla (min_n, max_n), default=(1, 1)
El límite inferior y superior del rango de n-valores para los diferentes n-gramas que se van a extraer. Se utilizarán todos los valores de n tales que min_n <= n <= max_n. Por ejemplo, un
ngram_rangede(1, 1)significa sólo unigramas,(1, 2)significa unigramas y bigramas, y(2, 2)significa sólo bigramas. Sólo se aplica sianalyzer is not callable.- analyzer{“word”, “char”, “char_wb”} o callable, default=”word”
Si la característica debe estar hecha de n-gramas de palabras o de n-gramas de caracteres. La opción “char_wb” crea n-gramas de caracteres sólo a partir del texto dentro de los límites de las palabras; los n-gramas en los bordes de las palabras se rellenan con espacio.
Si se pasa un invocable, se utiliza para extraer la secuencia de características de la entrada en bruto y sin procesar.
Distinto en la versión 0.21.
Desde la v0.21, si
inputesfilenameofile, los datos se leen primero del archivo y luego se pasan al analizador invocable dado.- n_featuresentero, default=(2 ** 20)
El número de características (columnas) en las matrices de salida. Es probable que un número pequeño de características provoque colisiones de hash, pero los números grandes causarán dimensiones de coeficiente más grandes en los aprendices lineales.
- binarybool, default=False.
Si es True, todos los contadores distintos de cero se establecen en 1. Esto es útil para modelos probabilísticos discretos que modelan eventos binarios en lugar de conteos enteros.
- norm{“l1”, “l2”}, default=”l2”
Norma utilizada para normalizar vectores de términos. None para no normalizar.
- alternate_signbool, default=True
Cuando es True, se añade un signo alternativo a las características para conservar aproximadamente el producto interno en el espacio mapeado (hashed), incluso para n_features pequeñas. Este enfoque es similar a la proyección aleatoria dispersa.
Nuevo en la versión 0.19.
- dtypetipo, default=np.float64
Tipo de la matriz devuelta por fit_transform() o transform().
Ver también
Ejemplos
>>> from sklearn.feature_extraction.text import HashingVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = HashingVectorizer(n_features=2**4) >>> X = vectorizer.fit_transform(corpus) >>> print(X.shape) (4, 16)
Métodos
Devuelve un invocable que maneja el preprocesamiento, tokenización y la generación de n-gramas.
Devuelve una función para preprocesar el texto antes de la tokenización.
Devuelve una función que divide una cadena en una secuencia de tokens.
Decodifica la entrada en una cadena de símbolos Unicode.
No hace nada: este transformador no tiene estado.
Transforma una secuencia de documentos en una matriz documento-término (document-term).
Obtiene los parámetros para este estimador.
Construye o busca la lista efectiva de palabras funcionales.
No hace nada: este transformador no tiene estado.
Establece los parámetros de este estimador.
Transforma una secuencia de documentos en una matriz documento-término (document-term).
- build_analyzer()¶
Devuelve un invocable que maneja el preprocesamiento, tokenización y la generación de n-gramas.
- Devuelve
- analyzer: callable
Una función para manejar el preprocesamiento, tokenización y la generación de n-gramas.
- build_preprocessor()¶
Devuelve una función para preprocesar el texto antes de la tokenización.
- Devuelve
- preprocessor: callable
Una función para preprocesar el texto antes de la tokenización.
- build_tokenizer()¶
Devuelve una función que divide una cadena en una secuencia de tokens.
- Devuelve
- tokenizer: callable
Una función para dividir una cadena en una secuencia de tokens.
- decode()¶
Decodifica la entrada en una cadena de símbolos Unicode.
La estrategia de decodificación depende de los parámetros del vectorizador.
- Parámetros
- docstr
La cadena a decodificar.
- Devuelve
- doc: str
Una cadena de símbolos Unicode.
- fit()¶
No hace nada: este transformador no tiene estado.
- Parámetros
- Xndarray de forma [n_samples, n_features]
Datos de entrenamiento.
- fit_transform()¶
Transforma una secuencia de documentos en una matriz documento-término (document-term).
- Parámetros
- Xiterable over raw text documents, length = n_samples
Muestras. Cada muestra debe ser un documento de texto (ya sea bytes o cadenas unicode, nombre de archivo u objeto de archivo, dependiendo del argumento del constructor) que será tokenizado y mapeado (hashed).
- yany
Ignorado. Este parámetro sólo existe por compatibilidad con sklearn.pipeline.Pipeline.
- Devuelve
- Xmatriz dispersa de forma (n_samples, n_features)
Matriz documento-término (document-term).
- get_params()¶
Obtiene los parámetros para este estimador.
- Parámetros
- deepbool, default=True
Si es True, devolverá los parámetros para este estimador y los subobjetos contenidos que son estimadores.
- Devuelve
- paramsdict
Los nombres de los parámetros mapeados a sus valores.
- get_stop_words()¶
Construye o busca la lista efectiva de palabras funcionales.
- Devuelve
- stop_words: list o None
Una lista de palabras funcionales.
- partial_fit()¶
No hace nada: este transformador no tiene estado.
Este método sólo está ahí para marcar el hecho de que este transformador puede funcionar en una configuración de transmisión (streaming).
- Parámetros
- Xndarray de forma [n_samples, n_features]
Datos de entrenamiento.
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto en estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma<component>__<parameter>para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia de estimador
Instancia del estimador.
- transform()¶
Transforma una secuencia de documentos en una matriz documento-término (document-term).
- Parámetros
- Xiterable over raw text documents, length = n_samples
Muestras. Cada muestra debe ser un documento de texto (ya sea bytes o cadenas unicode, nombre de archivo u objeto de archivo, dependiendo del argumento del constructor) que será tokenizado y mapeado (hashed).
- Devuelve
- Xmatriz dispersa de forma (n_samples, n_features)
Matriz documento-término (document-term).