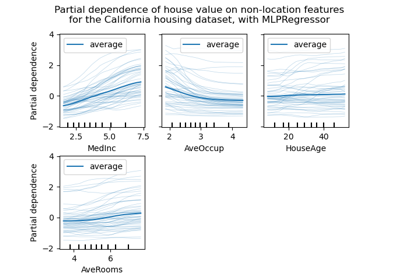
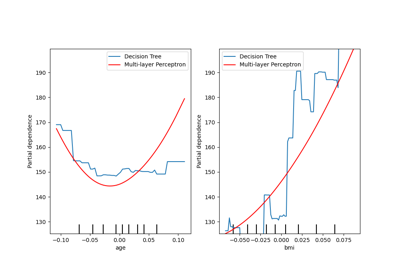
sklearn.neural_network.MLPRegressor¶
- class sklearn.neural_network.MLPRegressor¶
Regresor Perceptrón multicapa.
Este modelo optimiza la pérdida cuadrada utilizando LBFGS o el descenso de gradiente estocástico.
Nuevo en la versión 0.18.
- Parámetros
- hidden_layer_sizestupla, length = n_layers - 2, default=(100,)
El elemento i-ésimo representa el número de neuronas en la i-ésima capa oculta.
- activation{“identity”, “logistic”, “tanh”, “relu”}, default=”relu”
Función de activación para la capa oculta.
“identity”, activación no-op, útil para implementar el cuello de botella lineal, devuelve f(x) = x
“logistic”, la función sigmoide logística, devuelve f(x) = 1 / (1 + exp(-x)).
“tanh”, la función tangente hiperbólica, devuelve f(x) = tanh(x).
“relu”, la función de unidad lineal rectificada, devuelve f(x) = max(0, x)
- solver{“lbfgs”, “sgd”, “adam”}, default=”adam”
El solucionador para la optimización de la ponderación.
“lbfgs” es un optimizador en la familia de los métodos cuasi-Newton.
“sgd” se refiere al descenso de gradiente estocástico.
“adam” se refiere a un optimizador basado en el gradiente estocástico propuesto por Kingma, Diederik y Jimmy Ba
Nota: El solucionador por defecto “adam” funciona bastante bien en conjuntos de datos relativamente grandes (con miles de muestras de entrenamiento o más) en términos de tiempo de entrenamiento y puntuación de validación. Sin embargo, para conjuntos de datos pequeños, “lbfgs” puede converger más rápido y funcionar mejor.
- alphafloat, default=0.0001
Parámetro de penalización L2 (término de regularización).
- batch_sizeint, default=”auto”
Tamaño de los minilotes para los optimizadores estocásticos. Si el solucionador es “lbfgs”, el clasificador no utilizará minilotes. Cuando se establece en «auto»,
batch_size=min(200, n_samples)- learning_rate{“constant”, “invscaling”, “adaptive”}, default=”constant”
Programación de la tasa de aprendizaje para las actualizaciones de ponderación.
“constant” es una tasa de aprendizaje constante dada por “learning_rate_init”.
“invscaling” disminuye gradualmente la tasa de aprendizaje
learning_rate_en cada paso de tiempo “t” utilizando un exponente de escala inversa de “power_t”. effective_learning_rate = learning_rate_init / pow(t, power_t)“adaptive” mantiene la tasa de aprendizaje constante a “learning_rate_init” mientras la pérdida asociada al entrenamiento siga disminuyendo. Cada vez que dos épocas consecutivas no consiguen disminuir la pérdida asociada al entrenamiento en al menos tol, o no consiguen aumentar la puntuación de validación en al menos tol si “early_stopping” está activado, la tasa de aprendizaje actual se divide por 5.
Sólo se utiliza cuando solver=”sgd”.
- learning_rate_initdouble, default=0.001
La tasa de aprendizaje inicial utilizada. Controla el tamaño del paso en la actualización de las ponderaciones. Sólo se utiliza cuando solver=”sgd” o “adam”.
- power_tdouble, default=0.5
El exponente de la tasa de aprendizaje de escala inversa. Se utiliza en la actualización de la tasa de aprendizaje efectiva cuando learning_rate se establece en “invscaling”. Sólo se utiliza cuando solver=”sgd”.
- max_iterint, default=200
Número máximo de iteraciones. El solucionador itera hasta la convergencia (determinada por “tol”) o este número de iteraciones. Para los solucionadores estocásticos (“sgd”, “adam”), ten en cuenta que esto determina el número de épocas (cuántas veces se utilizará cada punto de datos), no el número de pasos del gradiente.
- shufflebool, default=True
Si se revuelven las muestras en cada iteración. Sólo se utiliza cuando solver=”sgd” o “adam”.
- random_stateentero, instancia de RandomState, default=None
Determina la generación de números aleatorios para la inicialización de las ponderaciones y el sesgo, la división de entrenamiento-prueba si se utiliza la parada anticipada, y el muestreo por lotes cuando solver=”sgd” o “adam”. Pasa un int para obtener resultados reproducibles a través de múltiples llamadas a la función. Ver Glosario.
- tolfloat, default=1e-4
Tolerancia para la optimización. Cuando la pérdida o la puntuación no mejora en al menos
tolduranten_iter_no_changeiteraciones consecutivas, a menos quelearning_rateesté establecido en “adaptive”, se considera que se ha alcanzado la convergencia y se detiene el entrenamiento.- verbosebool, default=False
Si se imprimen mensajes de progreso en stdout.
- warm_startbool, default=False
Cuando se establece en True, reutiliza la solución de la llamada previa a fit como inicialización, de lo contrario, sólo borra la solución previa. Ver el Glosario.
- momentumfloat, default=0.9
Momentum para la actualización del descenso de gradiente. Debe estar entre 0 y 1. Sólo se utiliza cuando solver=”sgd”.
- nesterovs_momentumbool, default=True
Si se utiliza el momentum de Nesterov. Sólo se utiliza cuando solver=”sgd” y momentum > 0.
- early_stoppingbool, default=False
Si se utiliza la parada anticipada para terminar el entrenamiento cuando la puntuación de validación no está mejorando. Si se establece como verdadero, se apartará automáticamente el 10% de los datos de entrenamiento como validación y terminará el entrenamiento cuando la puntuación de validación no mejore al menos en
tolduranten_iter_no_changeépocas consecutivas. Sólo es efectivo cuando solver=”sgd” o “adam”- validation_fractionfloat, default=0.1
La proporción de los datos de entrenamiento que se reservan como conjunto de validación para la parada anticipada. Debe estar entre 0 y 1. Sólo se utiliza si early_stopping es True
- beta_1float, default=0.9
Tasa de decaimiento exponencial para las estimaciones del vector del primer momento en adam, debe estar en [0, 1). Sólo se utiliza cuando solver=”adam”
- beta_2float, default=0.999
Tasa de decaimiento exponencial para las estimaciones del vector del segundo momento en adam, debe estar en [0, 1). Sólo se utiliza cuando solver=”adam”
- epsilonfloat, default=1e-8
Valor para la estabilidad numérica en adam. Sólo se utiliza cuando solver=”adam”
- n_iter_no_changeint, default=10
Número máximo de épocas para no cumplir con la mejora de
tol. Sólo efectivo cuando solver=”sgd” o “adam”Nuevo en la versión 0.20.
- max_funint, default=15000
Sólo se utiliza cuando solver=”lbfgs”. Número máximo de llamadas a la función. El solucionador itera hasta la convergencia (determinada por “tol”), hasta que el número de iteraciones alcanza max_iter, o hasta este número de llamadas a la función. Ten en cuenta que el número de llamadas a la función será mayor o igual que el número de iteraciones para el MLPRegressor.
Nuevo en la versión 0.22.
- Atributos
- loss_float
La pérdida actual calculada con la función de pérdida.
- best_loss_float
La pérdida mínima alcanzada por el solucionador a lo largo del ajuste.
- loss_curve_ : list de forma (
n_iter_,)list de forma ( El i-ésimo elemento en la lista representa la pérdida en la i-ésima iteración.
- t_int
El número de muestras de entrenamiento consideradas por el solucionador durante el ajuste.
- coefs_list de forma (n_layers - 1,)
El elemento i-ésimo en la lista representa la matriz de ponderación correspondiente a la capa i.
- intercepts_list de forma (n_layers - 1,)
El i-ésimo elemento en la lista representa el vector de sesgo correspondiente a la capa i + 1.
- n_iter_int
El número de iteraciones que ha ejecutado el solucionador.
- n_layers_int
Número de capas.
- n_outputs_int
Número de salidas.
- out_activation_str
Nombre de la función de activación de salida.
- loss_curve_list de forma (n_iters,)
Valor de pérdida evaluado al final de cada paso de entrenamiento.
- t_int
Matemáticamente equivale a
n_iters * X.shape[0], significatime_stepy es utilizado por el programador de la tasa de aprendizaje del optimizador.
Notas
El MLPRegressor entrena de forma iterativa ya que en cada paso de tiempo se calculan las derivadas parciales de la función de pérdida con respecto a los parámetros del modelo para actualizar los parámetros.
También puede tener un término de regularización añadido a la función de pérdida que reduce los parámetros del modelo para evitar el sobreajuste.
Esta implementación funciona con datos representados como arreglos numpy densos y dispersos de valores de punto flotante.
Referencias
- Hinton, Geoffrey E.
«Connectionist learning procedures.» Artificial intelligence 40.1 (1989): 185-234.
- Glorot, Xavier, y Yoshua Bengio. «Understanding the difficulty of
training deep feedforward neural networks.» International Conference on Artificial Intelligence and Statistics. 2010.
- He, Kaiming, et al. «Delving deep into rectifiers: Surpassing human-level
performance on imagenet classification.» arXiv preprint arXiv:1502.01852 (2015).
- Kingma, Diederik, y Jimmy Ba. «Adam: A method for stochastic
optimization.» arXiv preprint arXiv:1412.6980 (2014).
Ejemplos
>>> from sklearn.neural_network import MLPRegressor >>> from sklearn.datasets import make_regression >>> from sklearn.model_selection import train_test_split >>> X, y = make_regression(n_samples=200, random_state=1) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, ... random_state=1) >>> regr = MLPRegressor(random_state=1, max_iter=500).fit(X_train, y_train) >>> regr.predict(X_test[:2]) array([-0.9..., -7.1...]) >>> regr.score(X_test, y_test) 0.4...
Métodos
Ajusta el modelo a la matriz de datos X y objetivo(s) y.
Obtiene los parámetros para este estimador.
Predice utilizando el modelo de perceptrón multicapa.
Devuelve el coeficiente de determinación \(R^2\) de la predicción.
Establece los parámetros de este estimador.
- fit()¶
Ajusta el modelo a la matriz de datos X y objetivo(s) y.
- Parámetros
- Xndarray o matriz dispersa de forma (n_samples, n_features)
Los datos de entrada.
- yndarray de forma (n_samples,) o (n_samples, n_outputs)
Los valores objetivo (etiquetas de clase en clasificación, números reales en regresión).
- Devuelve
- selfdevuelve un modelo MLP entrenado.
- get_params()¶
Obtiene los parámetros para este estimador.
- Parámetros
- deepbool, default=True
Si es True, devolverá los parámetros para este estimador y los subobjetos contenidos que son estimadores.
- Devuelve
- paramsdict
Nombres de parámetros mapeados a sus valores.
- property partial_fit¶
Actualiza el modelo con una sola iteración sobre los datos dados.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Los datos de entrada.
- yndarray de forma (n_samples,)
Los valores objetivo.
- Devuelve
- selfdevuelve un modelo MLP entrenado.
- predict()¶
Predice utilizando el modelo de perceptrón multicapa.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Los datos de entrada.
- Devuelve
- yndarray de forma (n_samples, n_outputs)
Los valores predichos.
- score()¶
Devuelve el coeficiente de determinación \(R^2\) de la predicción.
El coeficiente \(R^2\) se define como \((1 - \frac{u}{v})\), donde \(u\) es la suma de cuadrados de los residuos
((y_true - y_pred) ** 2).sum()y \(v\) es la suma total de cuadrados((y_true - y_true.mean()) ** 2).sum(). La mejor puntuación posible es 1.0 y puede ser negativa (porque el modelo puede ser arbitrariamente peor). Un modelo constante que siempre predice el valor esperado dey, sin tener en cuenta las características de entrada, obtendría una puntuación \(R^2\) de 0.0.- Parámetros
- Xarray-like de forma (n_samples, n_features)
Muestras de prueba. Para algunos estimadores puede ser una matriz de núcleo precalculada o una lista de objetos genéricos con forma
(n_samples, n_samples_fitted), donden_samples_fittedes el número de muestras utilizadas en el ajuste para el estimador.- yarray-like de forma (n_samples,) o (n_samples, n_outputs)
Valores verdaderos para
X.- sample_weightarray-like de forma (n_samples,), default=None
Ponderaciones de muestras.
- Devuelve
- scorefloat
\(R^2\) de
self.predict(X)con respecto ay.
Notas
La puntuación \(R^2\) utilizada al llamar a
scoreen un regresor utilizamultioutput='uniform_average'desde la versión 0.23 para mantener la consistencia con el valor predeterminado der2_score. Esto influye en el métodoscorede todos los regresores de salida múltiple (excepto paraMultiOutputRegressor).
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto en estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma<component>__<parameter>para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia del estimador
Instancia del estimador.