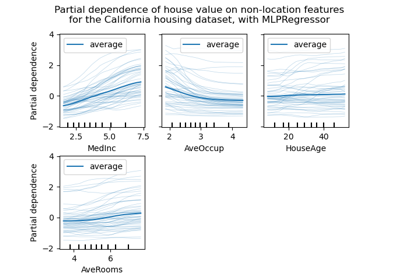
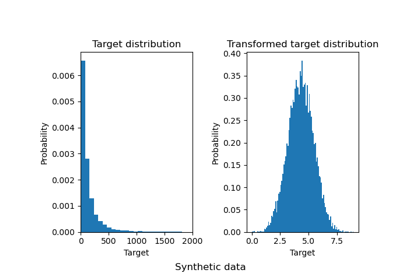
sklearn.preprocessing.QuantileTransformer¶
- class sklearn.preprocessing.QuantileTransformer¶
Transforma las características utilizando la información de los cuantiles.
Este método transforma las características para que sigan una distribución uniforme o normal. Por lo tanto, para una característica determinada, esta transformación tiende a repartir los valores más frecuentes. También reduce el impacto de los valores atípicos (marginales): se trata, por tanto, de un esquema de preprocesamiento robusto.
La transformación se aplica a cada característica de forma independiente. Primero, se utiliza una estimación de la función de distribución acumulada de una característica para mapear los valores originales a una distribución uniforme. Luego, los valores obtenidos se mapean a la distribución de salida deseada utilizando la función cuantil asociada. Los valores de las características de los datos nuevos/no vistos que caen por debajo o por encima del rango ajustado serán mapeados a los límites de la distribución de salida. Ten en cuenta que esta transformación no es lineal. Puede distorsionar las correlaciones lineales entre las variables medidas en la misma escala, pero hace que las variables medidas en diferentes escalas sean más directamente comparables.
Lee más en el Manual de usuario.
Nuevo en la versión 0.19.
- Parámetros
- n_quantilesint, default=1000 o n_samples
Número de cuantiles a calcular. Corresponde al número de puntos de referencia utilizados para discretizar la función de distribución acumulada. Si n_quantiles es mayor que el número de muestras, n_quantiles se fija en el número de muestras, ya que un número mayor de cuantiles no proporciona una mejor aproximación del estimador de la función de distribución acumulada.
- output_distribution{“uniform”, “normal”}, default=”uniform”
Distribución marginal para los datos transformados. Las opciones son “uniform” (predeterminado) o “normal”.
- ignore_implicit_zerosbool, default=False
Sólo se aplica a las matrices dispersas. Si es True, las entradas dispersas de la matriz se descartan para calcular las estadísticas de cuantiles. Si es False, estas entradas se tratan como ceros.
- subsampleint, default=1e5
Número máximo de muestras utilizadas para estimar los cuantiles para eficiencia computacional. Ten en cuenta que el procedimiento de submuestreo puede diferir para matrices densas y dispersas de valores idénticos.
- random_stateentero, instancia de RandomState o None, default=None
Determina la generación de números aleatorios para el submuestreo y el suavizado del ruido. Por favor, consulta
subsamplepara más detalles. Pasa un número entero (int) para que los resultados sean reproducibles en varias invocaciones a la función. Ver Glosario- copybool, default=True
Establécelo en False para realizar una transformación in place y evitar una copia (si la entrada ya es un arreglo de numpy).
- Atributos
- n_quantiles_int
El número real de cuantiles utilizados para discretizar la función de distribución acumulada.
- quantiles_ndarray de forma (n_quantiles, n_features)
Los valores correspondientes a los cuantiles de referencia.
- references_ndarray de forma (n_quantiles, )
Cuantiles de referencias.
Ver también
quantile_transformFunción equivalente sin la API del estimador.
PowerTransformerRealizar el mapeo a una distribución normal utilizando una transformación de potencia.
StandardScalerRealiza una normalización más rápida, pero menos robusta a los valores atípicos.
RobustScalerRealiza una estandarización robusta que elimina la influencia de los valores atípicos, pero que no coloca los valores atípicos y los valores típicos en la misma escala.
Notas
Los NaNs son tratados como valores faltantes: no se tienen en cuenta en el ajuste y se mantienen en la transformación.
Para una comparación de los diferentes escaladores, transformadores y normalizadores, consulta examples/preprocessing/plot_all_scaling.py.
Ejemplos
>>> import numpy as np >>> from sklearn.preprocessing import QuantileTransformer >>> rng = np.random.RandomState(0) >>> X = np.sort(rng.normal(loc=0.5, scale=0.25, size=(25, 1)), axis=0) >>> qt = QuantileTransformer(n_quantiles=10, random_state=0) >>> qt.fit_transform(X) array([...])
Métodos
Calcula los cuantiles utilizados para la transformación.
Ajusta a los datos y luego los transforma.
Obtiene los parámetros para este estimador.
Retroproyección al espacio original.
Establece los parámetros de este estimador.
Transformación de los datos en función de las características.
- fit()¶
Calcula los cuantiles utilizados para la transformación.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Los datos utilizados para escalar a lo largo del eje de características. Si se proporciona una matriz dispersa, se convertirá en una
csc_matrixdispersa. Además, la matriz dispersa debe ser no negativa siignore_implicit_zeroses False.- yNone
Ignorado.
- Devuelve
- selfobject
Transformador ajustado.
- fit_transform()¶
Ajusta a los datos y luego los transforma.
Ajusta el transformador a
Xeycon los parámetros opcionalesfit_paramsy devuelve una versión transformada deX.- Parámetros
- Xarray-like de forma (n_samples, n_features)
Muestras de entrada.
- yarray-like de forma (n_samples,) o (n_samples, n_outputs), default=None
Valores objetivo (None para transformaciones no supervisadas).
- **fit_paramsdict
Parámetros de ajuste adicionales.
- Devuelve
- X_newarreglo ndarray de forma (n_samples, n_features_new)
Arreglo transformado.
- get_params()¶
Obtiene los parámetros para este estimador.
- Parámetros
- deepbool, default=True
Si es True, devolverá los parámetros para este estimador y los subobjetos contenidos que son estimadores.
- Devuelve
- paramsdict
Los nombres de los parámetros mapeados a sus valores.
- inverse_transform()¶
Retroproyección al espacio original.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Los datos utilizados para escalar a lo largo del eje de características. Si se proporciona una matriz dispersa, se convertirá en una
csc_matrixdispersa. Además, la matriz dispersa debe ser no negativa siignore_implicit_zeroses False.
- Devuelve
- Xt{ndarray, sparse matrix} de (n_samples, n_features)
Los datos proyectados.
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto en estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma<component>__<parameter>para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia del estimador
Instancia del estimador.
- transform()¶
Transformación de los datos en función de las características.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Los datos utilizados para escalar a lo largo del eje de características. Si se proporciona una matriz dispersa, se convertirá en una
csc_matrixdispersa. Además, la matriz dispersa debe ser no negativa siignore_implicit_zeroses False.
- Devuelve
- Xt{ndarray, sparse matrix} de forma (n_samples, n_features)
Los datos proyectados.