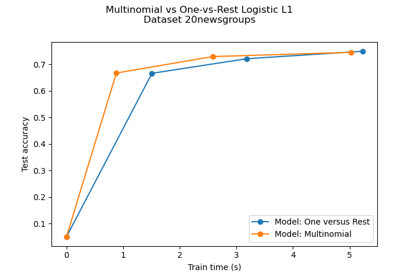
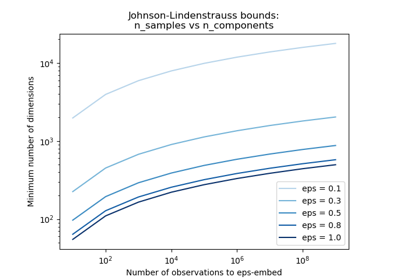
sklearn.datasets.fetch_20newsgroups_vectorized¶
- sklearn.datasets.fetch_20newsgroups_vectorized()¶
Cargar y vectorizar el conjunto de datos de 20 grupos de noticias (clasificación).
Descargar si es necesario.
Esta es una función de conveniencia; la transformación se realiza utilizando la configuración por defecto de
CountVectorizer. Para un uso más avanzado (filtrado de palabras de parada, extracción de n-gramas, etc.), combina fetch_20newsgroups con unCountVectorizerpersonalizado,HashingVectorizer,TfidfTransformeroTfidfVectorizer.Los recuentos resultantes se normalizan utilizando
sklearn.preprocessing.normalizea menos que normalize se establezca en False.Clases
20
Total de muestras
18846
Dimensionalidad
130107
Característica
real
Lee más en la Manual de usuario.
- Parámetros
- subconjunto{“train”, “test”, “all”}, default=”train”
Seleccione el conjunto de datos a cargar: “train” para el conjunto de entrenamiento, “test” para el conjunto de prueba, “all” para ambos, con ordenación aleatoria.
- removetuple, default=()
Puede contener cualquier subconjunto de (“headers”, “footers”, “quotes”). Cada uno de ellos es un tipo de texto que será detectado y eliminado de los mensajes de los grupos de noticias, evitando que los clasificadores se ajusten en exceso a los metadatos.
Los «headers» eliminan los encabezados de los grupos de noticias, los «footers» eliminan los bloques al final de los mensajes que parecen firmas, y las «quotes» eliminan las líneas que parecen citar otro mensaje.
- data_homestr, default=None
Especifique una carpeta de descarga y de caché para los conjuntos de datos. Si es None, todos los datos de scikit-learn se almacenan en las subcarpetas “~/scikit_learn_data”.
- download_if_missingbool, default=True
Si es False, lanza un IOError si los datos no están disponibles localmente en lugar de intentar descargar los datos desde el sitio de origen.
- return_X_ybool, default=False
Si es True, devuelve
(data.data, data.target)en lugar de un objeto Bunch.Nuevo en la versión 0.20.
- normalizebool, default=True
Si es True, normaliza el vector de características de cada documento a la norma unitaria usando
sklearn.preprocessing.normalize.Nuevo en la versión 0.22.
- as_framebool, default=False
Si es True, los datos son un DataFrame de pandas que incluye columnas con los dtypes apropiados (numérico, cadena o categórico). El objetivo es un DataFrame de pandas o una Serie dependiendo del número de
target_columns.Nuevo en la versión 0.24.
- Devuelve
- bunch
Bunch Objeto tipo diccionario, con los siguientes atributos.
- data: {sparse matrix, dataframe} de forma (n_samples, n_features)
La matriz de datos de entrada. Si
as_frameesTrue,dataes un DataFrame de pandas con columnas dispersas.- target: {ndarray, series} de forma (n_samples,)
Las etiquetas del objetivo. Si
as_frameesTrue,targetson Series de pandas.- target_names: lista de shape (n_clases,)
Los nombres de las clases objetivo.
- DESCR: str
La descripción completa del conjunto de datos.
- frame: dataframe de forma (n_samples, n_features + 1)
Sólo está presente cuando
as_frame=True. DataFrame de pandas condataytarget.Nuevo en la versión 0.24.
- (data, target) : tupla si
return_X_yes Truetupla si datosyobjetivotendrían el formato definido en la descripción delBunchanterior.Nuevo en la versión 0.20.
- bunch