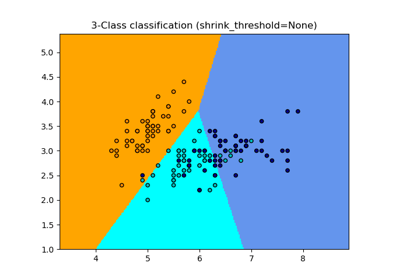
sklearn.neighbors.NearestCentroid¶
- class sklearn.neighbors.NearestCentroid¶
Clasificador de centroides más cercano.
Cada clase está representada por su centroide, con muestras de prueba clasificadas a la clase con el centro más cercano.
Más información en el Manual de usuario.
- Parámetros
- metriccadena de caracteres o invocable
La métrica a utilizar cuando se calcula la distancia entre instancias en un arreglo de características. Si la métrica es una cadena o un invocable, debe ser una de las opciones permitidas por metrics.pairwise.pairwise_distances para su parámetro de métrica. El centroide de las muestras correspondientes a cada clase es el punto desde el que se minimiza la suma de las distancias (según la métrica) de todas las muestras que pertenecen a esa clase en particular. Si se proporciona la métrica «manhattan», este centroide es la mediana y para todas las demás métricas, el centroide se establece ahora como la media.
Distinto en la versión 0.19:
metric='precomputed'fue obsoleto y ahora plantea un error- shrink_thresholdflotante, default=None
Umbral para reducir los centroides para eliminar características.
- Atributos
- centroids_array-like de forma (n_classes, n_features)
Centroide de cada clase.
- classes_arreglo de forma (n_classes,)
Etiquetas de clase únicas.
Ver también
KNeighborsClassifierClasificador de vecinos más cercanos.
Notas
Cuando se utiliza para la clasificación de texto con vectores tf-idf, este clasificador también se conoce como el clasificador Rocchio.
Referencias
Tibshirani, R., Hastie, T., Narasimhan, B., & Chu, G. (2002). Diagnosis of multiple cancer types by shrunken centroids of gene expression. Proceedings of the National Academy of Sciences of the United States of America, 99(10), 6567-6572. The National Academy of Sciences.
Ejemplos
>>> from sklearn.neighbors import NearestCentroid >>> import numpy as np >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = NearestCentroid() >>> clf.fit(X, y) NearestCentroid() >>> print(clf.predict([[-0.8, -1]])) [1]
Métodos
Ajusta el modelo NearestCentroid según los datos de formación dados.
Obtiene los parámetros para este estimador.
Realiza la clasificación en un arreglo de vectores de prueba X.
Devuelve la precisión media en los datos de prueba y las etiquetas dados.
Establece los parámetros de este estimador.
- fit()¶
Ajusta el modelo NearestCentroid según los datos de formación dados.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Vector de entrenamiento, donde n_samples es el número de muestras y n_features es el número de características. Ten en cuenta que la reducción de centroides no se puede utilizar con matrices dispersas.
- yarray-like de forma (n_samples,)
Valores objetivo (enteros)
- get_params()¶
Obtiene los parámetros para este estimador.
- Parámetros
- deepbooleano, default=True
Si es True, devolverá los parámetros para este estimador y los subobjetos contenidos que son estimadores.
- Devuelve
- paramsdict
Nombres de parámetros mapeados a sus valores.
- predict()¶
Realiza la clasificación en un arreglo de vectores de prueba X.
Se devuelve la clase C predicha para cada muestra en X.
- Parámetros
- Xarray-like de forma (n_samples, n_features)
- Devuelve
- Cndarray de forma (n_samples,)
Notas
Si el parámetro del constructor métrico es «precomputed», se asume que X es la matriz de distancia entre los datos a predecir y
self.centroids_.
- score()¶
Devuelve la precisión media en los datos de prueba y las etiquetas dados.
En la clasificación multietiqueta, se trata de la precisión del subconjunto, que es una métrica rigurosa, ya que se requiere para cada muestra que cada conjunto de etiquetas sea predicho correctamente.
- Parámetros
- Xarray-like de forma (n_samples, n_features)
Muestras de prueba.
- yarray-like de forma (n_samples,) o (n_samples, n_outputs)
Etiquetas verdaderas para
X.- sample_weightarray-like de forma (n_samples,), default=None
Ponderaciones de muestra.
- Devuelve
- scoreflotante
Precisión media de
self.predict(X)con respecto ay.
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto en estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma ``<component>__<parameter>` para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia del estimador
Instancia de estimador.