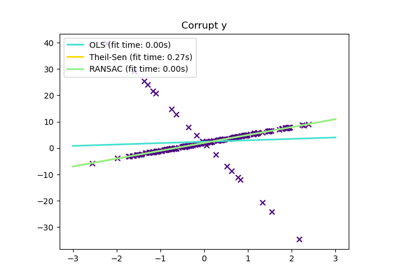
sklearn.linear_model.RANSACRegressor¶
- class sklearn.linear_model.RANSACRegressor¶
Algoritmo RANSAC (RANdom Sample Consensus).
RANSAC es un algoritmo iterativo para la estimación robusta de parámetros a partir de un subconjunto de valores típicos (inliers) del conjunto completo de datos.
Más información en el Manual de usuario.
- Parámetros
- base_estimatorobjeto, default=None
Objeto estimador base que implementa los siguientes métodos:
fit(X, y): Ajustar el modelo a los datos de entrenamiento y a los valores objetivo dados.``score(X, y)`: Devuelve la precisión media en los datos de prueba dados, que se utiliza para el criterio de parada definido por
stop_score. Además, la puntuación se utiliza para decidir cuál de dos conjuntos de consenso igualmente grandes se elige como el mejor.predict(X): Devuelve los valores predichos utilizando el modelo lineal, que se utiliza para calcular el error residual utilizando la función de pérdida.
Si
base_estimatores None, entoncesLinearRegressionse utiliza para los valores objetivo de dtype float.Ten en cuenta que la implementación actual sólo soporta estimadores de regresión.
- min_samplesint (>= 1) o float ([0, 1]), default=None
Número mínimo de muestras elegidas aleatoriamente de los datos originales. Tratada como un número absoluto de muestras para
min_samples >= 1, tratada como un número relativoceil(min_samples * X.shape[0]) formin_samples < 1. Esto se suele elegir como el número mínimo de muestras necesarias para estimar elbase_estimatordado. Por defecto se asume un estimadorsklearn.linear_model.LinearRegression()ymin_samplesse elige comoX.shape[1] + 1.- residual_thresholdfloat, default=None
Residuo máximo para que una muestra de datos sea clasificada como un valor típico (inlier). Por defecto, el umbral se elige como la MAD (desviación absoluta de la mediana) de los valores objetivo
y.- is_data_validinvocable, default=None
Esta función se llama con los datos seleccionados aleatoriamente antes de ajustar el modelo a ellos:
is_data_valid(X, y). Si su valor de retorno es False, se omite la submuestra actual elegida aleatoriamente.- is_model_validinvocable, default=None
Esta función se llama con el modelo estimado y los datos seleccionados al azar:
is_model_valid(model, X, y). Si su valor de retorno es False, se omite la submuestra actual elegida aleatoriamente. Rechazar muestras con esta función es más costoso computacionalmente que conis_data_valid. Por lo tanto,is_model_validsólo debería utilizarse si el modelo estimado es necesario para tomar la decisión de rechazo.- max_trialsint, default=100
Número máximo de iteraciones para la selección de muestras aleatorias.
- max_skipsint, default=np.inf
Número máximo de iteraciones que se pueden omitir debido a que se encuentran valores típicos (inliers) cero o datos no válidos definidos por
is_data_valid, o modelos no válidos definidos poris_model_valid.Nuevo en la versión 0.19.
- stop_n_inliersint, default=np.inf
Detiene la iteración si se encuentra al menos este número de inliers.
- stop_scorefloat, default=np.inf
Detener la iteración si la puntuación es superior a este umbral.
- stop_probabilityflotante en el rango [0, 1], default=0.99
La iteración de RANSAC se detiene si al menos un conjunto libre de valores atípicos (outliers) de los datos de entrenamiento es muestreado en RANSAC. Esto requiere generar al menos N muestras (iteraciones):
N >= log(1 - probability) / log(1 - e**m)
donde la probabilidad (confianza) suele fijarse en un valor alto como 0.99 (el valor predeterminado) y e es la fracción actual de valores típicos (inliers) con respecto al número total de muestras.
- losscadena de caracteres, invocable, default=”absolute_loss”
Se admiten entradas de cadena, «absolute_loss» y «squared_loss» que encuentran la pérdida absoluta y la pérdida al cuadrado por muestra respectivamente.
Si
losses un invocable, entonces debe ser una función que toma dos arreglos como entradas, el valor verdadero y el predicho y devuelve un arreglo 1-D con el i-ésimo valor del arreglo correspondiente a la pérdida enX[i].Si la pérdida en una muestra es mayor que el
residual_threshold, entonces esta muestra se clasifica como un valor atípico.Nuevo en la versión 0.18.
- random_stateentero, instancia de RandomState, default=None
El generador utilizado para inicializar los centros. Pasa un int para una salida reproducible a través de múltiples llamadas a la función. Ver Glosario.
- Atributos
- estimator_object
Modelo mejor ajustado (copia del objeto
base_estimator).- n_trials_int
Número de ensayos de selección aleatoria hasta que se cumpla uno de los criterios de parada. Siempre es
<= max_trials.- inlier_mask_arreglo de booleanos de forma [n_samples]
Máscara booleana de valores típicos (inliers) clasificados como
True.- n_skips_no_inliers_int
Número de iteraciones omitidas debidas a encontrar cero inliers.
Nuevo en la versión 0.19.
- n_skips_invalid_data_int
Número de iteraciones omitidas debido a datos no válidos definidos por
is_data_valid.Nuevo en la versión 0.19.
- n_skips_invalid_model_int
Número de iteraciones omitidas debido a un modelo no válido definido por
is_model_valid.Nuevo en la versión 0.19.
Referencias
Ejemplos
>>> from sklearn.linear_model import RANSACRegressor >>> from sklearn.datasets import make_regression >>> X, y = make_regression( ... n_samples=200, n_features=2, noise=4.0, random_state=0) >>> reg = RANSACRegressor(random_state=0).fit(X, y) >>> reg.score(X, y) 0.9885... >>> reg.predict(X[:1,]) array([-31.9417...])
Métodos
Ajustar estimador usando el algoritmo RANSAC.
Obtiene los parámetros para este estimador.
Predice utilizando el modelo estimado.
Devuelve la puntuación de la predicción.
Establece los parámetros de este estimador.
- fit()¶
Ajustar estimador usando el algoritmo RANSAC.
- Parámetros
- Xarray-like o matriz dispersa, forma [n_samples, n_features]
Datos del entrenamiento.
- yarray-like de forma (n_samples,) o (n_samples, n_targets)
Valores objetivo.
- sample_weightarray-like de forma (n_samples,), default=None
Las ponderaciones individuales para cada muestra generan un error si se pasa sample_weight y el método de ajuste base_estimator no lo admite.
Nuevo en la versión 0.18.
- Errores posibles
- ValueError
Si no se ha podido encontrar un conjunto de consenso válido. Esto ocurre si
is_data_validyis_model_validdevuelven False para todas las submuestrasmax_trialselegidas aleatoriamente.
- get_params()¶
Obtiene los parámetros para este estimador.
- Parámetros
- deepbool, default=True
Si es True, devolverá los parámetros para este estimador y los subobjetos contenidos que son estimadores.
- Devuelve
- paramsdict
Nombres de parámetros mapeados a sus valores.
- predict()¶
Predice utilizando el modelo estimado.
Esta es una envoltura (wrapper) para
estimator_.predict(X).- Parámetros
- Xarreglo numpy de forma [n_samples, n_features]
- Devuelve
- yarreglo, forma = [n_samples] o [n_samples, n_targets]
Devuelve los valores predichos.
- score()¶
Devuelve la puntuación de la predicción.
Esta es una envoltura (wrapper) para
estimator_.score(X, y).- Parámetros
- Xarreglo numpy o matriz dispersa de forma [n_samples, n_features]
Datos del entrenamiento.
- yarreglo, forma = [n_samples] o [n_samples, n_targets]
Valores objetivo.
- Devuelve
- zfloat
Puntuación de la predicción.
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto con estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma<component>__<parameter>para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia del estimador
Instancia de estimador.