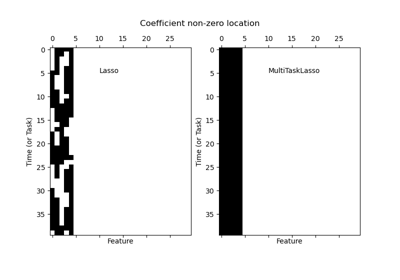
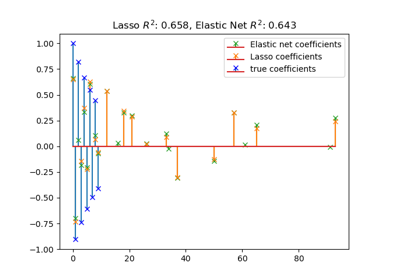
sklearn.linear_model.Lasso¶
- class sklearn.linear_model.Lasso¶
Modelo lineal entrenado con L1 a priori como regularizador (también conocido como Lasso)
El objetivo de optimización para Lasso es:
(1 / (2 * n_samples)) * ||y - Xw||^2_2 + alpha * ||w||_1
Técnicamente el modelo Lasso está optimizando la misma función objetivo que Elastic Net con
l1_ratio=1.0(sin penalización L2).Más información en el Manual de usuario.
- Parámetros
- alphafloat, default=1.0
Constante que multiplica el término L1. Por defecto es 1.0.
alpha = 0es equivalente a un mínimo cuadrado ordinario, resuelto por el objetoLinearRegression. Por razones numéricas, no se aconseja utilizaralpha = 0con el objetoLasso. Por ello, se debe utilizar el objetoLinearRegression.- fit_interceptbool, default=True
Si se calcula el intercepto para este modelo. Si se establece en False, no se utilizará ningún intercepto en los cálculos (es decir, se espera que los datos estén centrados).
- normalizebool, default=False
Este parámetro se ignora cuando
fit_interceptse establece en False. Si es True, los regresores X serán normalizados antes de la regresión restando la media y dividiendo por la norma l2. Si desea estandarizar, por favor utilizaStandardScalerantes de llamar afiten un estimador connormalize=False.- precompute“auto”, bool o array-like de forma (n_features, n_features), default=False
Si se utiliza una matriz Gram precalculada para acelerar los cálculos. Si se establece como
autose puede decidir. La matriz Gram también se puede pasar como argumento. Para entradas dispersas esta opción es siempreTruepara preservar la dispersión.- copy_Xbool, default=True
Si es
True, X se copiará; si no, puede sobrescribirse.- max_iterint, default=1000
El número máximo de iteraciones.
- tolfloat, default=1e-4
La tolerancia para la optimización: si las actualizaciones son menores que
tol, el código de optimización comprueba la optimización dela brecha dual y continúa hasta que sea menor quetol.- warm_startbool, default=False
Cuando se establece como True, reutiliza la solución de la llamada anterior a fit como inicialización, de lo contrario, sólo borra la solución anterior. Ver el Glosario.
- positivebool, default=False
Cuando se establece en
True, obliga a los coeficientes a ser positivos.- random_stateint, instancia RandomState, default=None
La semilla del generador de números pseudoaleatorios que selecciona una característica aleatoria para actualizar. Se utiliza cuando
selection== “random”. Pase un int para una salida reproducible a través de múltiples llamadas a la función. Ver Glosario.- selection{“cyclic”, “random”}, default=”cyclic”
Si se establece como “random”, se actualiza un coeficiente aleatorio en cada iteración en lugar de hacer un bucle sobre las características de forma secuencial por defecto. Esto (el ajuste a “random”) a menudo conduce a una convergencia significativamente más rápida, especialmente cuando tol es mayor que 1e-4.
- Atributos
- coef_ndarray de forma (n_features,) o (n_targets, n_features)
Vector de parámetros (w en la fórmula de la función de coste).
- dual_gap_float o ndarray de forma (n_targets,)
Dado el parámetro alpha, las brechas duales al final de la optimización, de la misma forma que cada observación de y.
sparse_coef_matriz dispersa de forma (n_features, 1) o (n_targets, n_features)Representación dispersa del
coef_ajustado.- intercept_float o ndarray de forma (n_targets,)
Término independiente en la función de decisión.
- n_iter_int o list de int
Número de iteraciones ejecutadas por el solucionador de descenso de coordenadas para alcanzar la tolerancia especificada.
Notas
El algoritmo utilizado para ajustar el modelo es el descenso de coordenadas.
Para evitar la duplicación innecesaria de memoria, el argumento X del método fit debe pasarse directamente como un arreglo numpy Fortran-contiguo.
Ejemplos
>>> from sklearn import linear_model >>> clf = linear_model.Lasso(alpha=0.1) >>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2]) Lasso(alpha=0.1) >>> print(clf.coef_) [0.85 0. ] >>> print(clf.intercept_) 0.15...
Métodos
Ajusta el modelo con el descenso de coordenadas.
Obtiene los parámetros para este estimador.
Calcula la ruta de la red elástica con el descenso de coordenadas.
Predice utilizando el modelo lineal.
Devuelve el coeficiente de determinación \(R^2\) de la predicción.
Establece los parámetros de este estimador.
- fit()¶
Ajusta el modelo con el descenso de coordenadas.
- Parámetros
- X{ndarray, sparse matrix} de (n_samples, n_features)
Datos.
- y{ndarray, sparse matrix} de forma (n_samples,) o (n_samples, n_targets)
Objetivo. Se convertirá al dtype de X si es necesario.
- sample_weightfloat o array-like de forma (n_samples,), default=None
Ponderación de la muestra.
Nuevo en la versión 0.23.
- check_inputbool, default=True
Permite omitir varias comprobaciones de entrada. No uses este parámetro a menos que sepas lo que haces.
Notas
El descenso de coordenadas es un algoritmo que considera cada columna de datos a la vez, por lo que convertirá automáticamente la entrada X como un arreglo numpy Fortran-contiguo si es necesario.
Para evitar la reasignación de memoria se aconseja asignar los datos iniciales en la memoria directamente utilizando ese formato.
- get_params()¶
Obtiene los parámetros para este estimador.
- Parámetros
- deepbool, default=True
Si es True, devolverá los parámetros para este estimador y los subobjetos contenidos que son estimadores.
- Devuelve
- paramsdict
Nombres de parámetros mapeados a sus valores.
- static path()¶
Calcula la ruta de la red elástica con el descenso de coordenadas.
La función de optimización de la red elástica varía para las monosalidas y multisalidas.
Para las tareas monosalida es:
1 / (2 * n_samples) * ||y - Xw||^2_2 + alpha * l1_ratio * ||w||_1 + 0.5 * alpha * (1 - l1_ratio) * ||w||^2_2
Para tareas multisalida es:
(1 / (2 * n_samples)) * ||Y - XW||^Fro_2 + alpha * l1_ratio * ||W||_21 + 0.5 * alpha * (1 - l1_ratio) * ||W||_Fro^2
Donde:
||W||_21 = \sum_i \sqrt{\sum_j w_{ij}^2}
es decir, la suma de la norma de cada fila.
Más información en el Manual de usuario.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Datos de entrenamiento. Pásalos directamente como datos Fortran-contiguos para evitar la duplicación innecesaria de memoria. Si
yes monosalida entoncesXpuede ser disperso.- y{array-like, sparse matrix} de forma (n_samples,) o (n_samples, n_outputs)
Valores objetivo.
- l1_ratiofloat, default=0.5
Número entre 0 y 1 pasado a la red elástica (escalado entre penalizaciones l1 y l2).
l1_ratio=1corresponde al Lasso.- epsfloat, default=1e-3
Longitud de la ruta.
eps=1e-3significa quealpha_min / alpha_max = 1e-3.- n_alphasint, default=100
Número de alfas a lo largo de la ruta de regularización.
- alphasndarray, default=None
Lista de alfas donde calcular los modelos. Si es None los alfas se establecen automáticamente.
- precompute“auto”, bool o array-like de forma (n_features, n_features), default=”auto”
Si se utiliza una matriz de Gram precalculada para acelerar los cálculos. Si se establece como
'auto'podemos decidir. La matriz de Gram también se puede pasar como argumento.- Xyarray-like de forma (n_features,) o (n_features, n_outputs), default=None
Xy = np.dot(X.T, y) que puede ser precalculado. Es útil sólo cuando la matriz Gram está precalculada.
- copy_Xbool, default=True
Si es
True, X se copiará; si no, puede sobrescribirse.- coef_initndarray de forma (n_features, ), default=None
Los valores iniciales de los coeficientes.
- verbosebool o int, default=False
Cantidad de verbosidad.
- return_n_iterbool, default=False
Si se devuelve o no el número de iteraciones.
- positivebool, default=False
Si se establece como True, obliga a los coeficientes a ser positivos. (Sólo se permite cuando
y.ndim ==1).- check_inputbool, default=True
Si se establece en False, se omiten las comprobaciones de validación de la entrada (incluyendo la matriz Gram cuando se proporciona). Se asume que son manejadas por el llamador.
- **paramskwargs
Argumentos de palabras clave que se pasan al solucionador de descenso de coordenadas.
- Devuelve
- alphasndarray de forma (n_alphas,)
Los alfas a lo largo de la ruta donde se calculan los modelos.
- coefsndarray de forma (n_features, n_alphas) o (n_outputs, n_features, n_alphas)
Coeficientes a lo largo de la ruta.
- dual_gapsndarray de forma (n_alphas,)
Las brechas duales al final de la optimización para cada alfa.
- n_iterslist de int
El número de iteraciones tomadas por el optimizador de descenso de coordenadas para alcanzar la tolerancia especificada para cada alfa. (Es devuelto cuando
return_n_iterestá establecido a True).
Notas
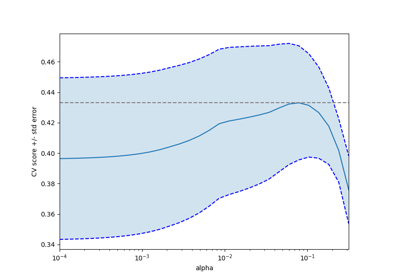
Para un ejemplo, ver examples/linear_model/plot_lasso_coordinate_descent_path.py.
- predict()¶
Predice utilizando el modelo lineal.
- Parámetros
- Xarray-like o matriz dispersa, forma (n_samples, n_features)
Muestras.
- Devuelve
- Carreglo, forma (n_samples,)
Devuelve los valores predichos.
- score()¶
Devuelve el coeficiente de determinación \(R^2\) de la predicción.
El coeficiente \(R^2\) se define como \((1 - \frac{u}{v})\), donde \(u\) es la suma residual de cuadrados
((y_true - y_pred) ** 2).sum()y \(v\) es la suma total de cuadrados((y_true - y_true.mean()) ** 2).sum(). La mejor puntuación posible es 1,0 y puede ser negativa (porque el modelo puede ser arbitrariamente peor). Un modelo constante que siempre predice el valor esperado dey, sin tener en cuenta las características de entrada, obtendría una puntuación \(R^2\) de 0,0.- Parámetros
- Xarray-like de forma (n_samples, n_features)
Muestras de prueba. Para algunos estimadores puede ser una matriz de núcleo precalculada o una lista de objetos genéricos en su lugar con forma
(n_samples, n_samples_fitted), donden_samples_fittedes el número de muestras utilizadas en el ajuste para el estimador.- yarray-like de forma (n_samples,) o (n_samples, n_outputs)
Valores verdaderos para
X.- sample_weightarray-like de forma (n_samples,), default=None
Ponderaciones de la muestra.
- Devuelve
- scorefloat
\(R^2\) de
self.predict(X)con respecto ay.
Notas
La puntuación \(R^2\) utilizada al llamar a
scoreen un regresor utilizamultioutput='uniform_average'desde la versión 0.23 para mantener la consistencia con el valor predeterminado der2_score. Esto influye en el métodoscorede todos los regresores de salida múltiple (excepto paraMultiOutputRegressor).
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto con estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma<component>__<parameter>para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia de estimador
Instancia del estimador.
- property sparse_coef_¶
Representación dispersa del
coef_ajustado.