Nota
Haz clic aquí para descargar el código completo del ejemplo o para ejecutar este ejemplo en tu navegador a través de Binder
Matriz de confusión¶
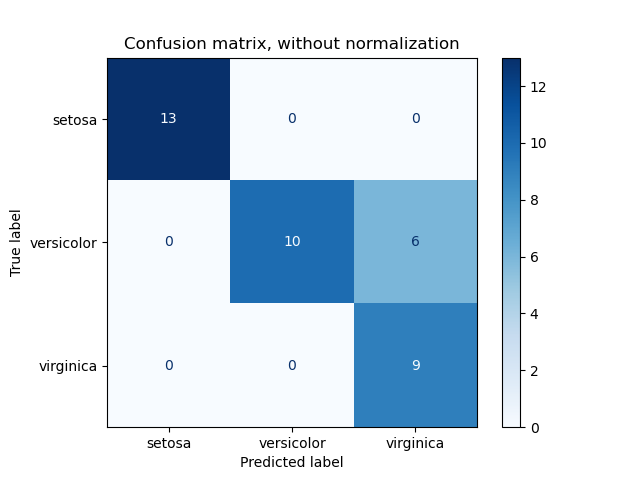
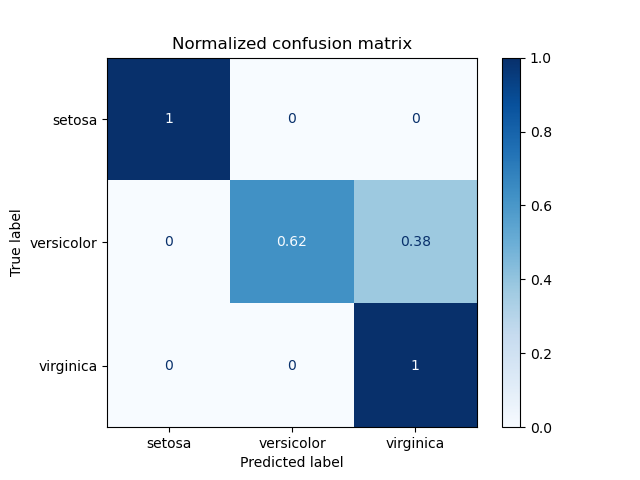
Ejemplo de uso de la matriz de confusión para evaluar la calidad del resultado de un clasificador en el conjunto de datos del iris. Los elementos diagonales representan el número de puntos para los que la etiqueta predicha es igual a la verdadera, mientras que los elementos fuera de la diagonal son los que el clasificador ha etiquetado erróneamente. Cuanto más altos sean los valores diagonales de la matriz de confusión, mejor, ya que indican muchas predicciones correctas.
Las figuras muestran la matriz de confusión con y sin normalización por tamaño de soporte de clase (número de elementos en cada clase). Este tipo de normalización puede ser interesante en caso de desequilibrio de clases para tener una interpretación más visual de qué clase se está clasificando mal.
Aquí los resultados no son tan buenos como podrían serlo, ya que nuestra elección del parámetro de regularización C no fue la mejor. En las aplicaciones de la vida real, este parámetro suele elegirse utilizando Ajustar los hiperparámetros de un estimador.
Out:
Confusion matrix, without normalization
[[13 0 0]
[ 0 10 6]
[ 0 0 9]]
Normalized confusion matrix
[[1. 0. 0. ]
[0. 0.62 0.38]
[0. 0. 1. ]]
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import plot_confusion_matrix
# import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
class_names = iris.target_names
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# Run classifier, using a model that is too regularized (C too low) to see
# the impact on the results
classifier = svm.SVC(kernel='linear', C=0.01).fit(X_train, y_train)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
titles_options = [("Confusion matrix, without normalization", None),
("Normalized confusion matrix", 'true')]
for title, normalize in titles_options:
disp = plot_confusion_matrix(classifier, X_test, y_test,
display_labels=class_names,
cmap=plt.cm.Blues,
normalize=normalize)
disp.ax_.set_title(title)
print(title)
print(disp.confusion_matrix)
plt.show()
Tiempo total de ejecución del script: (0 minutos 0.266 segundos)