Nota
Haz clic en aquí para descargar el código de ejemplo completo o para ejecutar este ejemplo en tu navegador a través de Binder
Parada anticipada del descenso de gradiente estocástico¶
El descenso de gradiente estocástico es una técnica de optimización que minimiza una función de pérdida de forma estocástica, realizando un paso de descenso de gradiente muestra a muestra. En particular, es un método muy eficaz para ajustar modelos lineales.
Al ser un método estocástico, la función de pérdida no es necesariamente decreciente en cada iteración, y la convergencia sólo se garantiza en la expectativa. Por esta razón, el seguimiento de la convergencia en la función de pérdida puede ser difícil.
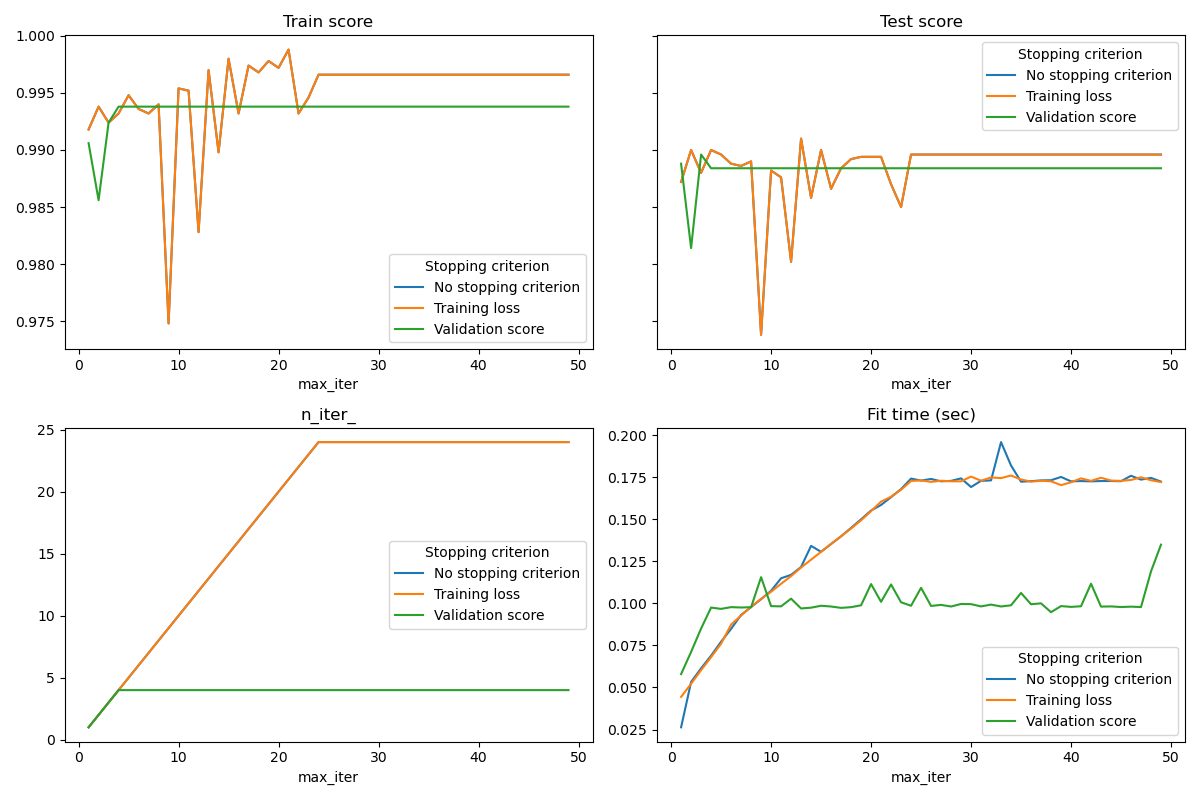
Otro enfoque consiste en controlar la convergencia en una puntuación de validación. En este caso, los datos de entrada se dividen en un conjunto de entrenamiento y un conjunto de validación. El modelo se ajusta al conjunto de entrenamiento y el criterio de parada se basa en la puntuación de predicción calculada en el conjunto de validación. Esto nos permite encontrar el menor número de iteraciones que es suficiente para construir un modelo que generaliza bien a los datos no vistos y reduce la posibilidad de sobreajuste de los datos de entrenamiento.
Esta estrategia de parada anticipada se activa si early_stopping=True; en caso contrario, el criterio de parada sólo utiliza la pérdida asociada al entrenamiento en todos los datos de entrada. Para controlar mejor la estrategia de parada anticipada, podemos especificar un parámetro validation_fraction que establece la fracción del conjunto de datos de entrada que se reserva para calcular la puntuación de validación. La optimización continuará hasta que la puntuación de validación no mejore en al menos tol durante las últimas iteraciones de n_iter_no_change. El número real de iteraciones está disponible en el atributo n_iter_.
Este ejemplo ilustra cómo la parada anticipada puede utilizarse en el modelo SGDClassifier para conseguir casi la misma precisión que un modelo construido sin parada anticipada. Esto puede reducir significativamente el tiempo de entrenamiento. Tenga en cuenta que las puntuaciones difieren entre los criterios de parada incluso desde las primeras iteraciones porque algunos de los datos de entrenamiento se mantienen con el criterio de parada de validación.
Out:
No stopping criterion: .................................................
Training loss: .................................................
Validation score: .................................................
# Authors: Tom Dupre la Tour
#
# License: BSD 3 clause
import time
import sys
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.utils._testing import ignore_warnings
from sklearn.exceptions import ConvergenceWarning
from sklearn.utils import shuffle
print(__doc__)
def load_mnist(n_samples=None, class_0='0', class_1='8'):
"""Load MNIST, select two classes, shuffle and return only n_samples."""
# Load data from http://openml.org/d/554
mnist = fetch_openml('mnist_784', version=1)
# take only two classes for binary classification
mask = np.logical_or(mnist.target == class_0, mnist.target == class_1)
X, y = shuffle(mnist.data[mask], mnist.target[mask], random_state=42)
if n_samples is not None:
X, y = X[:n_samples], y[:n_samples]
return X, y
@ignore_warnings(category=ConvergenceWarning)
def fit_and_score(estimator, max_iter, X_train, X_test, y_train, y_test):
"""Fit the estimator on the train set and score it on both sets"""
estimator.set_params(max_iter=max_iter)
estimator.set_params(random_state=0)
start = time.time()
estimator.fit(X_train, y_train)
fit_time = time.time() - start
n_iter = estimator.n_iter_
train_score = estimator.score(X_train, y_train)
test_score = estimator.score(X_test, y_test)
return fit_time, n_iter, train_score, test_score
# Define the estimators to compare
estimator_dict = {
'No stopping criterion':
linear_model.SGDClassifier(n_iter_no_change=3),
'Training loss':
linear_model.SGDClassifier(early_stopping=False, n_iter_no_change=3,
tol=0.1),
'Validation score':
linear_model.SGDClassifier(early_stopping=True, n_iter_no_change=3,
tol=0.0001, validation_fraction=0.2)
}
# Load the dataset
X, y = load_mnist(n_samples=10000)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5,
random_state=0)
results = []
for estimator_name, estimator in estimator_dict.items():
print(estimator_name + ': ', end='')
for max_iter in range(1, 50):
print('.', end='')
sys.stdout.flush()
fit_time, n_iter, train_score, test_score = fit_and_score(
estimator, max_iter, X_train, X_test, y_train, y_test)
results.append((estimator_name, max_iter, fit_time, n_iter,
train_score, test_score))
print('')
# Transform the results in a pandas dataframe for easy plotting
columns = [
'Stopping criterion', 'max_iter', 'Fit time (sec)', 'n_iter_',
'Train score', 'Test score'
]
results_df = pd.DataFrame(results, columns=columns)
# Define what to plot (x_axis, y_axis)
lines = 'Stopping criterion'
plot_list = [
('max_iter', 'Train score'),
('max_iter', 'Test score'),
('max_iter', 'n_iter_'),
('max_iter', 'Fit time (sec)'),
]
nrows = 2
ncols = int(np.ceil(len(plot_list) / 2.))
fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(6 * ncols,
4 * nrows))
axes[0, 0].get_shared_y_axes().join(axes[0, 0], axes[0, 1])
for ax, (x_axis, y_axis) in zip(axes.ravel(), plot_list):
for criterion, group_df in results_df.groupby(lines):
group_df.plot(x=x_axis, y=y_axis, label=criterion, ax=ax)
ax.set_title(y_axis)
ax.legend(title=lines)
fig.tight_layout()
plt.show()
Tiempo total de ejecución del script: (1 minutos 2.986 segundos)