Nota
Haz clic en aquí para descargar el código de ejemplo completo o para ejecutar este ejemplo en tu navegador a través de Binder
Combinar predictores mediante el apilamiento (stacking)¶
El apilamiento (stacking) se refiere a un método para mezclar estimadores. En esta estrategia, algunos estimadores se ajustan individualmente a algunos datos de entrenamiento mientras que un estimador final se entrena utilizando las predicciones apiladas de estos estimadores base.
En este ejemplo, ilustramos el caso de uso en el que se apilan diferentes regresores y se utiliza un regresor lineal penalizado final para realizar la predicción. Comparamos el rendimiento de cada regresor individual con la estrategia de apilamiento. El apilamiento mejora ligeramente el rendimiento general.
print(__doc__)
# Authors: Guillaume Lemaitre <g.lemaitre58@gmail.com>
# Maria Telenczuk <https://github.com/maikia>
# License: BSD 3 clause
Descargar conjunto de datos¶
Se utilizará el conjunto de datos Ames Housing que fue compilado por primera vez por Dean De Cock y que se hizo más conocido después de que se utilizara en el reto de Kaggle. Se trata de un conjunto de 1460 viviendas residenciales en Ames, Iowa, cada una descrita por 80 características. Lo utilizaremos para predecir el precio logarítmico final de las casas. En este ejemplo utilizaremos sólo las 20 características más interesantes elegidas mediante GradientBoostingRegressor() y limitaremos el número de entradas (aquí no entraremos en detalles sobre cómo seleccionar las características más interesantes).
El conjunto de datos Ames Housing no se suministra con scikit-learn, por lo que lo obtendremos de OpenML.
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.utils import shuffle
def load_ames_housing():
df = fetch_openml(name="house_prices", as_frame=True)
X = df.data
y = df.target
features = ['YrSold', 'HeatingQC', 'Street', 'YearRemodAdd', 'Heating',
'MasVnrType', 'BsmtUnfSF', 'Foundation', 'MasVnrArea',
'MSSubClass', 'ExterQual', 'Condition2', 'GarageCars',
'GarageType', 'OverallQual', 'TotalBsmtSF', 'BsmtFinSF1',
'HouseStyle', 'MiscFeature', 'MoSold']
X = X[features]
X, y = shuffle(X, y, random_state=0)
X = X[:600]
y = y[:600]
return X, np.log(y)
X, y = load_ames_housing()
Hacer un pipeline para preprocesar los datos¶
Antes de poder utilizar el conjunto de datos de Ames, tenemos que hacer un preprocesamiento. En primer lugar, el conjunto de datos tiene muchos valores faltantes. Para imputarlos, intercambiaremos los valores faltantes categóricos con la nueva categoría “missing”, mientras que los valores faltantes numéricos con la “media” de la columna. También codificaremos las categorías con
~sklearn.preprocessing.OneHotEncodero~sklearn.preprocessing.OrdinalEncoderdependiendo del tipo de modelo que vayamos a utilizar (modelo lineal o no lineal). Para facilitar este preprocesamiento haremos dos pipelines. Puedes saltarte esta sección si tus datos están listos para ser utilizados y no necesitan preprocesamiento
from sklearn.compose import make_column_transformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import StandardScaler
cat_cols = X.columns[X.dtypes == 'O']
num_cols = X.columns[X.dtypes == 'float64']
categories = [
X[column].unique() for column in X[cat_cols]]
for cat in categories:
cat[cat == None] = 'missing' # noqa
cat_proc_nlin = make_pipeline(
SimpleImputer(missing_values=None, strategy='constant',
fill_value='missing'),
OrdinalEncoder(categories=categories)
)
num_proc_nlin = make_pipeline(SimpleImputer(strategy='mean'))
cat_proc_lin = make_pipeline(
SimpleImputer(missing_values=None,
strategy='constant',
fill_value='missing'),
OneHotEncoder(categories=categories)
)
num_proc_lin = make_pipeline(
SimpleImputer(strategy='mean'),
StandardScaler()
)
# transformation to use for non-linear estimators
processor_nlin = make_column_transformer(
(cat_proc_nlin, cat_cols),
(num_proc_nlin, num_cols),
remainder='passthrough')
# transformation to use for linear estimators
processor_lin = make_column_transformer(
(cat_proc_lin, cat_cols),
(num_proc_lin, num_cols),
remainder='passthrough')
Pila de predictores en un solo conjunto de datos¶
A veces resulta tedioso encontrar el modelo que mejor funcione en un conjunto de datos determinado. El apilamiento ofrece una alternativa al combinar los resultados de varios aprendices, sin necesidad de elegir un modelo específico. El rendimiento del apilamiento suele acercarse al mejor modelo y a veces puede superar el rendimiento de predicción de cada modelo individual.
Aquí combinamos 3 algoritmos de aprendizaje (lineales y no lineales) y utilizamos un regresor de cresta para combinar sus resultados.
Nota: aunque haremos nuevos pipelines con los procesadores que escribimos en la sección anterior para los 3 algoritmos de aprendizaje, el estimador final RidgeCV() no necesita preprocesar los datos ya que se alimentará con la salida ya preprocesada de los 3 algoritmos.
from sklearn.experimental import enable_hist_gradient_boosting # noqa
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import LassoCV
from sklearn.linear_model import RidgeCV
lasso_pipeline = make_pipeline(processor_lin,
LassoCV())
rf_pipeline = make_pipeline(processor_nlin,
RandomForestRegressor(random_state=42))
gradient_pipeline = make_pipeline(
processor_nlin,
HistGradientBoostingRegressor(random_state=0))
estimators = [('Random Forest', rf_pipeline),
('Lasso', lasso_pipeline),
('Gradient Boosting', gradient_pipeline)]
stacking_regressor = StackingRegressor(estimators=estimators,
final_estimator=RidgeCV())
Medir y graficar los resultados¶
Ahora podemos utilizar el conjunto de datos de Ames Housing para hacer las predicciones. Comprobamos el rendimiento de cada uno de los predictores individuales, así como del conjunto de los regresores.
La función
plot_regression_resultsse utiliza para graficar los objetivos predichos y verdaderos.
import time
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_validate, cross_val_predict
def plot_regression_results(ax, y_true, y_pred, title, scores, elapsed_time):
"""Scatter plot of the predicted vs true targets."""
ax.plot([y_true.min(), y_true.max()],
[y_true.min(), y_true.max()],
'--r', linewidth=2)
ax.scatter(y_true, y_pred, alpha=0.2)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.get_xaxis().tick_bottom()
ax.get_yaxis().tick_left()
ax.spines['left'].set_position(('outward', 10))
ax.spines['bottom'].set_position(('outward', 10))
ax.set_xlim([y_true.min(), y_true.max()])
ax.set_ylim([y_true.min(), y_true.max()])
ax.set_xlabel('Measured')
ax.set_ylabel('Predicted')
extra = plt.Rectangle((0, 0), 0, 0, fc="w", fill=False,
edgecolor='none', linewidth=0)
ax.legend([extra], [scores], loc='upper left')
title = title + '\n Evaluation in {:.2f} seconds'.format(elapsed_time)
ax.set_title(title)
fig, axs = plt.subplots(2, 2, figsize=(9, 7))
axs = np.ravel(axs)
for ax, (name, est) in zip(axs, estimators + [('Stacking Regressor',
stacking_regressor)]):
start_time = time.time()
score = cross_validate(est, X, y,
scoring=['r2', 'neg_mean_absolute_error'],
n_jobs=-1, verbose=0)
elapsed_time = time.time() - start_time
y_pred = cross_val_predict(est, X, y, n_jobs=-1, verbose=0)
plot_regression_results(
ax, y, y_pred,
name,
(r'$R^2={:.2f} \pm {:.2f}$' + '\n' + r'$MAE={:.2f} \pm {:.2f}$')
.format(np.mean(score['test_r2']),
np.std(score['test_r2']),
-np.mean(score['test_neg_mean_absolute_error']),
np.std(score['test_neg_mean_absolute_error'])),
elapsed_time)
plt.suptitle('Single predictors versus stacked predictors')
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.show()
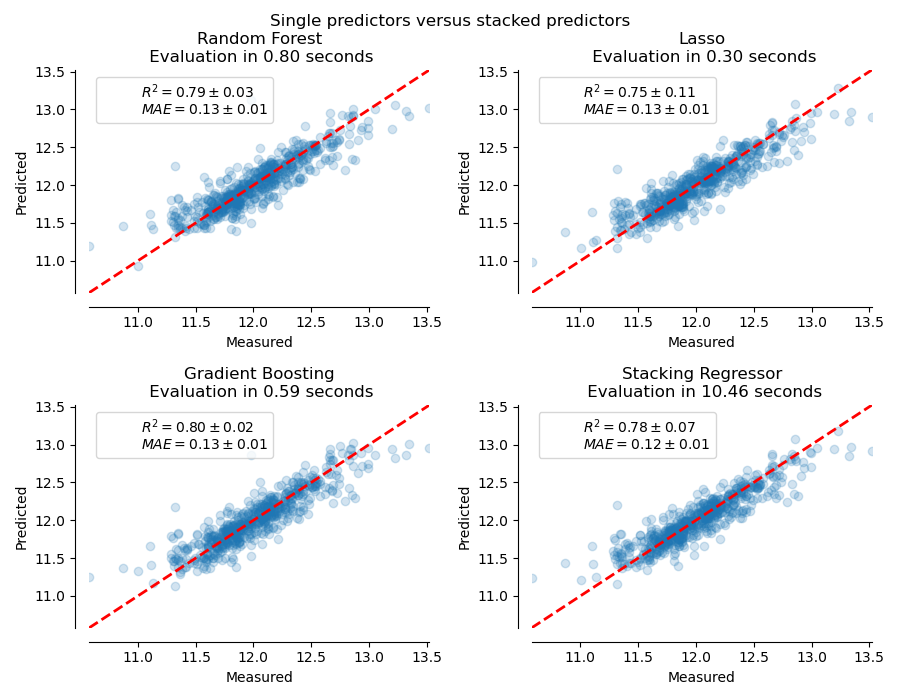
El regresor apilado (stacked) combinará los puntos fuertes de los diferentes regresores. Sin embargo, también vemos que el entrenamiento del regresor apilado es mucho más caro computacionalmente.
Tiempo total de ejecución del script: (0 minutos 24.138 segundos)