Nota
Haz clic en aquí para descargar el código de ejemplo completo o para ejecutar este ejemplo en tu navegador a través de Binder
Una demostración del algoritmo de Co-Clustering Espectral¶
Este ejemplo demuestra cómo generar un conjunto de datos y biclusterizarlo utilizando el algoritmo Co-Clustering Espectral.
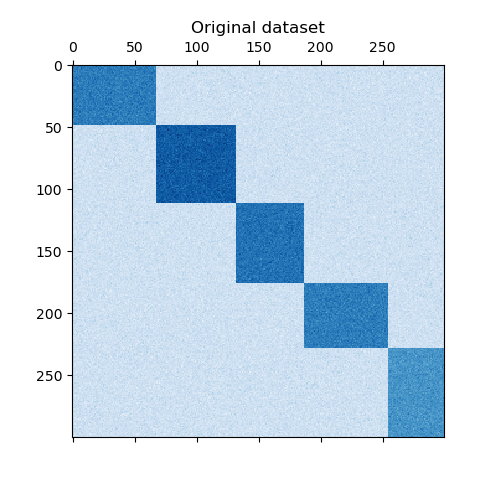
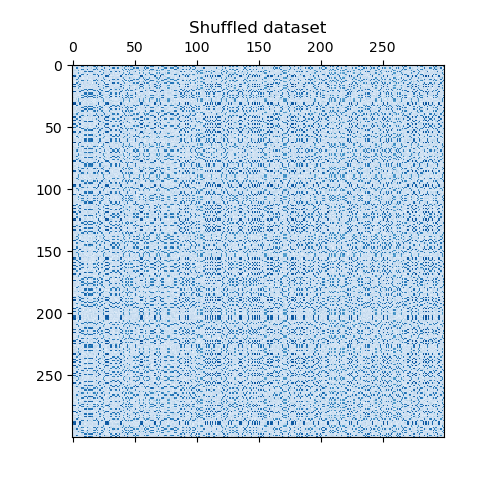
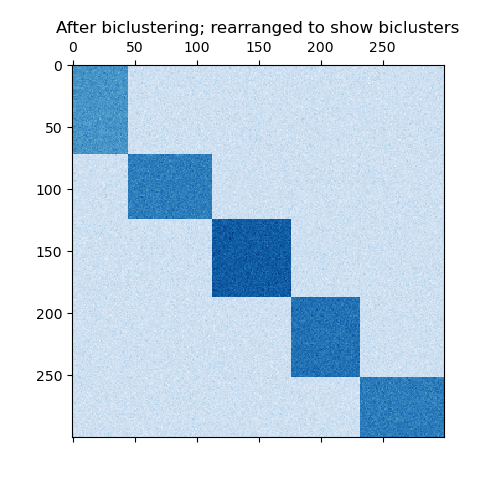
El conjunto de datos se genera mediante la función make_biclusters, que crea una matriz de valores pequeños e implanta biclusters con valores grandes. A continuación, las filas y columnas se barajan y se pasan al algoritmo de Co-Clustering Espectral. La reordenación de la matriz barajada para que los biclústeres sean contiguos muestra la precisión con la que el algoritmo encontró los biclústeres.
Out:
consensus score: 1.000
print(__doc__)
# Author: Kemal Eren <kemal@kemaleren.com>
# License: BSD 3 clause
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_biclusters
from sklearn.cluster import SpectralCoclustering
from sklearn.metrics import consensus_score
data, rows, columns = make_biclusters(
shape=(300, 300), n_clusters=5, noise=5,
shuffle=False, random_state=0)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
# shuffle clusters
rng = np.random.RandomState(0)
row_idx = rng.permutation(data.shape[0])
col_idx = rng.permutation(data.shape[1])
data = data[row_idx][:, col_idx]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
model = SpectralCoclustering(n_clusters=5, random_state=0)
model.fit(data)
score = consensus_score(model.biclusters_,
(rows[:, row_idx], columns[:, col_idx]))
print("consensus score: {:.3f}".format(score))
fit_data = data[np.argsort(model.row_labels_)]
fit_data = fit_data[:, np.argsort(model.column_labels_)]
plt.matshow(fit_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
plt.show()
Tiempo total de ejecución del script: (0 minutos 0.696 segundos)