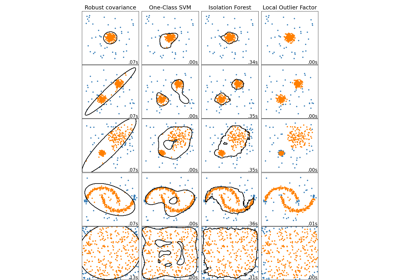
sklearn.covariance.EllipticEnvelope¶
- class sklearn.covariance.EllipticEnvelope¶
Un objeto para detectar valores atípicos en un conjunto de datos con distribución Gaussiana.
Más información en el Manual de usuario.
- Parámetros
- store_precisionbooleano, default=True
Especifica si se almacena la precisión estimada.
- assume_centeredbooleano, default=False
Si es True, se calcula el apoyo de estimados de ubicación y covarianza robustos, y se recalcula una estimación de covarianza desde ahí, sin centrar los datos. Útil para trabajar con datos cuya media es significativamente igual a cero pero no es exactamente cero. Si es False, la ubicación y covarianza robusta se calculan directamente con el algoritmo FastMCD sin tratamiento adicional.
- support_fractionflotante, default=None
La proporción de puntos que se incluirán en el apoyo de la estimación MCD en bruto. Si es None, se utilizará el valor mínimo de support_fraction dentro del algoritmo:
[n_sample + n_features + 1] / 2. El rango es (0, 1).- contaminationflotante, default=0.1
La cantidad de contaminación del conjunto de datos, es decir, la proporción de valores atípicos en el conjunto de datos. El rango es (0, 0.5).
- random_stateentero, instancia de RandomState o None, default=None
Determina el generador de números pseudo aleatorios para barajar los datos. Pasa un int para resultados reproducibles a través de múltiples llamadas de función. Ver :term:
Glosario <random_state>.
- Atributos
- location_ndarray de forma (n_features,)
Ubicación robusta estimada.
- covariance_ndarray de forma (n_features, n_features)
Matriz de covarianza robusta estimada.
- precision_ndarray de forma (n_features, n_features)
Matrix pseudo inversa estimada. (almacenada sólo si store_precision es True)
- support_ndarray de forma (n_samples,)
Una máscara de las observaciones que se han utilizado para calcular las estimaciones robustas de la ubicación y forma.
- offset_float
Desplazamiento usado para definir la función de decisión de las puntuaciones crudas. Tenemos la relación:
decision_function = score_samples - offset_. El desplazamiento depende del parámetro de contaminación y se define de tal manera que obtengamos el número esperado de valores atípicos (muestras con función de decisión < 0) en el entrenamiento.Nuevo en la versión 0.20.
- raw_location_ndarray de forma (n_features,)
La ubicación robusta estimada antes de la corección y la reponderación.
- raw_covariance_ndarray de forma (n_features, n_features)
La covarianza robusta estimada antes de la corección y la reponderación.
- raw_support_ndarray de forma (n_samples,)
Una máscara de las observaciones que se han utilizado para calcular las estimaciones robustas de la ubicación y forma, antes de la corrección y el reponderado.
- dist_ndarray de forma (n_samples,)
Distancias mahalanobis de las observaciones del conjunto de entrenamiento (en el cual se llama
fit).
Ver también
Notas
La detección de valores atípicos de la estimación de covarianza quizás se rompa o no tenga buen rendimiento en ajustes de alta dimensionalidad. En particular, uno siempre debería tener cuidado al trabajar con
n_samples > n_features ** 2.Referencias
- 1
Rousseeuw, P.J., Van Driessen, K. «A fast algorithm for the minimum covariance determinant estimator» Technometrics 41(3), 212 (1999)
Ejemplos
>>> import numpy as np >>> from sklearn.covariance import EllipticEnvelope >>> true_cov = np.array([[.8, .3], ... [.3, .4]]) >>> X = np.random.RandomState(0).multivariate_normal(mean=[0, 0], ... cov=true_cov, ... size=500) >>> cov = EllipticEnvelope(random_state=0).fit(X) >>> # predict returns 1 for an inlier and -1 for an outlier >>> cov.predict([[0, 0], ... [3, 3]]) array([ 1, -1]) >>> cov.covariance_ array([[0.7411..., 0.2535...], [0.2535..., 0.3053...]]) >>> cov.location_ array([0.0813... , 0.0427...])
Métodos
Aplica una corrección a los estimados de Determinante de Covarianza Mínima cruda.
Calcula la función de decisión de las observaciones dadas.
Calcula el Error Cuadrático Medio entre dos estimadores de covarianza.
Encaja el modelo EllipticEnvelope.
Realiza el encaje en X y devuelve etiquetas para X.
Obtiene los parámetros para este estimador.
Colector para la matriz de precisión.
Calcula las distancias de mahalanobis cuadráticas de las observaciones dadas.
Predice las etiquetas (1 típico, -1 atípico) de X de acuerdo al modelo ajustado.
Reponderación de estimados de Determinante de Covarianza Mínima.
Devuelve la precisión media en los datos y etiquetas de prueba dados.
Calcula las distancias de Mahalanobis negativas.
Establece los parámetros de este estimador.
- correct_covariance()¶
Aplica una corrección a los estimados de Determinante de Covarianza Mínima cruda.
Corrección usando el factor de corrección empírica sugerido por Rousseeuw y Van Driessen en [RVD].
- Parámetros
- dataarray-like de forma (n_samples, n_features)
La matriz de datos con p características y n muestras. El conjunto de datos debe ser el que fue utilizado para calcular las estimaciones en bruto.
- Devuelve
- covariance_correctedndarray de forma (n_features, n_features)
Estimado robusto de covarianza corregido.
Referencias
- RVD
A Fast Algorithm for the Minimum Covariance Determinant Estimator, 1999, American Statistical Association and the American Society for Quality, TECHNOMETRICS
- decision_function()¶
Calcula la función de decisión de las observaciones dadas.
- Parámetros
- Xarray-like de forma (n_samples, n_features)
La matriz de datos.
- Devuelve
- decisiónndarray de forma (n_samples,)
Función de decisión de las muestras. Es igual a las distancias de Mahalanobis desplazadas. El umbral para ser atípico es 0, lo cual garantiza la compatibilidad con otros algoritmos de detección de valores atípicos.
- error_norm()¶
Calcula el Error Cuadrático Medio entre dos estimadores de covarianza. (En el sentido de la norma Frobenius).
- Parámetros
- comp_covarray-like de forma (n_features, n_features)
La covarianza con la cual se compara.
- norm{«frobenius», «spectral»}, default=»frobenius»
El tipo de norma utilizada para calcular el error. Tipos de error disponibles: - “frobenius” (predeterminado): sqrt(tr(A^t.)) - “spectral”: sqrt(max(eigenvalues(A^t.A)) donde A es el error
(comp_cov - self.covariance_).- scalingbooleano, default=True
Si es True (predeterminado), la norma del error cuadrático es dividida por n_features. Si es False, la norma del error cuadrático no es reescalada.
- squaredbooleano, default=True
Si se calcula la norma de error cuadrático o la norma de error. Si es True (predeterminado) se devuelve la norma de error cuadrático. Si es False, se devuelve la norma de error.
- Devuelve
- resultfloat
El Error Cuadrático Medio (en el sentido de la norma Frobenius) entre los estimadores de covarianza
selfycomp_cov.
- fit()¶
Encaja el modelo EllipticEnvelope.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features)
Datos del entrenamiento.
- yIgnorado
No se utiliza, está presente para la coherencia de la API por convención.
- fit_predict()¶
Realiza el encaje en X y devuelve etiquetas para X.
Devuelve -1 para los valores atípicos y 1 para los valores típicos.
- Parámetros
- X{array-like, sparse matrix, dataframe} de forma (n_samples, n_features)
- yIgnorado
No se utiliza, está presente para la coherencia de la API por convención.
- Devuelve
- yndarray de forma (n_samples,)
1 para los valores típicos, -1 para los valores atípicos.
- get_params()¶
Obtiene los parámetros para este estimador.
- Parámetros
- deepbooleano, default=True
Si es True, devolverá los parámetros para este estimador y los subobjetos contenidos que son estimadores.
- Devuelve
- paramsdict
Nombres de parámetros asignados a sus valores.
- get_precision()¶
Colector para la matriz de precisión.
- Devuelve
- precision_array-like de forma (n_features, n_features)
La matriz de precisión asociada al objeto de covariancia actual.
- mahalanobis()¶
Calcula las distancias de mahalanobis cuadráticas de las observaciones dadas.
- Parámetros
- Xarray-like de forma (n_samples, n_features)
Las observaciones, las distancias Mahalanobis de lo que calculamos. Se asume que las observaciones se extraen de la misma distribución que utilizaron los datos en el ajuste.
- Devuelve
- distndarray de forma (n_samples,)
Distancias de Mahalanobis cuadráticas de las observaciones.
- predict()¶
Predice las etiquetas (1 típico, -1 atípico) de X de acuerdo al modelo ajustado.
- Parámetros
- Xarray-like de forma (n_samples, n_features)
La matriz de datos.
- Devuelve
- is_inlierndarray de forma (n_samples,)
Devuelve -1 para las anomalías/atípicos y +1 para los típicos.
- reweight_covariance()¶
Reponderación de estimados de Determinante de Covarianza Mínima.
El re-ponderado de observaciones utilizando el método de Rousseuw (equivalente a eliminar las observaciones atípicas del conjunto de datos antes de calcular los estimados de ubicación y covarianza) descrito en [RVDriessen].
- Parámetros
- dataarray-like de forma (n_samples, n_features)
La matriz de datos con p características y n muestras. El conjunto de datos debe ser el que fue utilizado para calcular las estimaciones en bruto.
- Devuelve
- location_reweightedndarray de forma (n_features,)
Estimado robusto de ubicación reponderado.
- covariance_reweightedndarray de forma (n_features, n_features)
Estimado robusto de covarianza reponderado.
- support_reweightedndarray de forma (n_samples,), dtype=bool
Una máscara de las observaciones que se han utilizado para calcular las estimaciones reponderadas robustas de la ubicación y forma.
Referencias
- RVDriessen
A Fast Algorithm for the Minimum Covariance Determinant Estimator, 1999, American Statistical Association and the American Society for Quality, TECHNOMETRICS
- score()¶
Devuelve la precisión media en los datos y etiquetas de prueba dados.
En la clasificación multietiqueta, se trata de la precisión del subconjunto, que es una métrica exigente, ya que se requiere para cada muestra que cada conjunto de etiquetas sea predicho correctamente.
- Parámetros
- Xarray-like de forma (n_samples, n_features)
Muestras de prueba.
- yarray-like de la forma (n_samples,) o (n_samples, n_outputs)
Etiquetas verdaderas para X.
- sample_weightarray-like de forma (n_samples,), default=None
Ponderados de muestras.
- Devuelve
- scorefloat
Precisión media de self.predict(X) con relación a y.
- score_samples()¶
Calcula las distancias de Mahalanobis negativas.
- Parámetros
- Xarray-like de forma (n_samples, n_features)
La matriz de datos.
- Devuelve
- negative_mahal_distancesarray-like de forma (n_samples,)
Opuesto de las distancias de Mahalanobis.
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto en estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma<component>__<parameter>para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia del estimador
Instancia del estimador.