Nota
Haz clic en aquí para descargar el código completo del ejemplo o para ejecutar este ejemplo en tu navegador a través de Binder
Clasificación MNIST mediante logística multinomial + L1¶
Aquí ajustamos una regresión logística multinomial con la pena L1 en un subconjunto de la clasificación de dígitos MNIST. Utilizamos el algoritmo SAGA para este propósito: es un solucionador rápido cuando el número de muestras es significativamente mayor que el número de características y es capaz de optimizar finamente las funciones objetivo no lisas que es el caso con la l1-penalty. La exactitud de la prueba alcanza > 0.8, mientras que los vectores de peso permanecen sparse y por lo tanto más fácilmente interpretable.
Obsérvese que esta precisión de este modelo lineal penalizado por l1 es significativamente inferior a la que puede alcanzar un modelo lineal penalizado por l2 o un modelo perceptrón multicapa no lineal en este conjunto de datos.
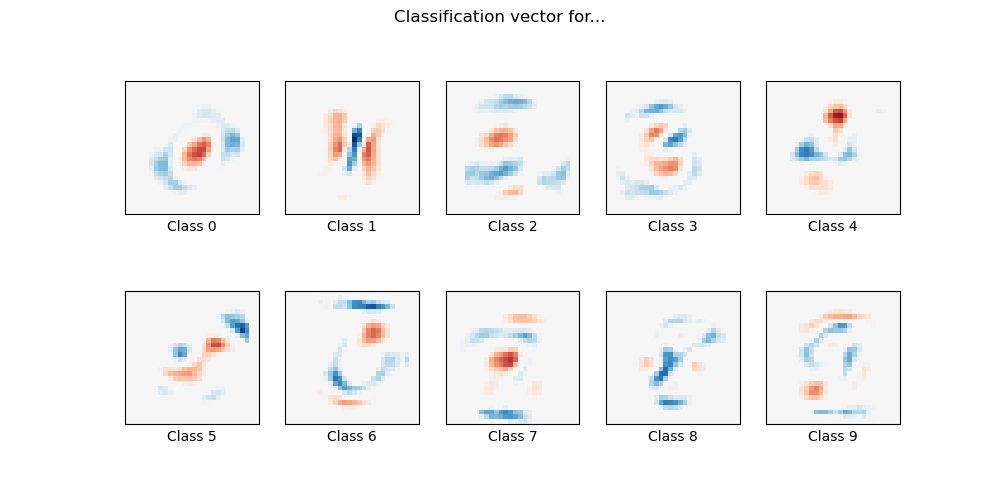
Out:
Sparsity with L1 penalty: 79.95%
Test score with L1 penalty: 0.8322
Example run in 278.205 s
import time
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.utils import check_random_state
print(__doc__)
# Author: Arthur Mensch <arthur.mensch@m4x.org>
# License: BSD 3 clause
# Turn down for faster convergence
t0 = time.time()
train_samples = 5000
# Load data from https://www.openml.org/d/554
X, y = fetch_openml('mnist_784', version=1, return_X_y=True, as_frame=False)
random_state = check_random_state(0)
permutation = random_state.permutation(X.shape[0])
X = X[permutation]
y = y[permutation]
X = X.reshape((X.shape[0], -1))
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=train_samples, test_size=10000)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Turn up tolerance for faster convergence
clf = LogisticRegression(
C=50. / train_samples, penalty='l1', solver='saga', tol=0.1
)
clf.fit(X_train, y_train)
sparsity = np.mean(clf.coef_ == 0) * 100
score = clf.score(X_test, y_test)
# print('Best C % .4f' % clf.C_)
print("Sparsity with L1 penalty: %.2f%%" % sparsity)
print("Test score with L1 penalty: %.4f" % score)
coef = clf.coef_.copy()
plt.figure(figsize=(10, 5))
scale = np.abs(coef).max()
for i in range(10):
l1_plot = plt.subplot(2, 5, i + 1)
l1_plot.imshow(coef[i].reshape(28, 28), interpolation='nearest',
cmap=plt.cm.RdBu, vmin=-scale, vmax=scale)
l1_plot.set_xticks(())
l1_plot.set_yticks(())
l1_plot.set_xlabel('Class %i' % i)
plt.suptitle('Classification vector for...')
run_time = time.time() - t0
print('Example run in %.3f s' % run_time)
plt.show()
Tiempo total de ejecución del script: (4 minutos 38.364 segundos)