Nota
Haz clic en aquí para descargar el código de ejemplo completo o para ejecutar este ejemplo en tu navegador a través de Binder
Parada anticipada de la Potenciación de Gradiente¶
El refuerzo de gradiente es una técnica de ensamblaje en la que se combinan varios algoritmos de aprendizaje débiles (árboles de regresión) para obtener un único modelo más poderoso, de forma iterativa.
El soporte de parada temprana en Potenciación de Gradiente nos permite encontrar el menor número de iteraciones que sea suficiente para construir un modelo que generalice bien a los datos no vistos.
El concepto de parada temprana es sencillo. Especificamos una validation_fraction que denota la fracción del conjunto de datos que se mantendrá al margen del entrenamiento para evaluar la pérdida de validación del modelo. El modelo de potenciación de gradiente se entrena utilizando el conjunto de entrenamiento y se evalúa utilizando el conjunto de validación. Cuando se añade cada etapa adicional del árbol de regresión, se utiliza el conjunto de validación para puntuar el modelo. Esto continúa hasta que las puntuaciones del modelo en las últimas etapas de n_iter_no_change no mejoren al menos en tol. Después de esto, se considera que el modelo ha convergido y se «detiene tempranamente» la adición de etapas.
El número de etapas del modelo final está disponible en el atributo n_estimators_.
Este ejemplo ilustra cómo la parada temprana puede utilizarse en el modelo GradientBoostingClassifier para lograr casi la misma precisión que un modelo construido sin parada temprana utilizando muchos menos estimadores. Esto puede reducir significativamente el tiempo de entrenamiento, el uso de memoria y la latencia de la predicción.
# Authors: Vighnesh Birodkar <vighneshbirodkar@nyu.edu>
# Raghav RV <rvraghav93@gmail.com>
# License: BSD 3 clause
import time
import numpy as np
import matplotlib.pyplot as plt
from sklearn import ensemble
from sklearn import datasets
from sklearn.model_selection import train_test_split
print(__doc__)
data_list = [datasets.load_iris(), datasets.load_digits()]
data_list = [(d.data, d.target) for d in data_list]
data_list += [datasets.make_hastie_10_2()]
names = ['Iris Data', 'Digits Data', 'Hastie Data']
n_gb = []
score_gb = []
time_gb = []
n_gbes = []
score_gbes = []
time_gbes = []
n_estimators = 500
for X, y in data_list:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=0)
# We specify that if the scores don't improve by atleast 0.01 for the last
# 10 stages, stop fitting additional stages
gbes = ensemble.GradientBoostingClassifier(n_estimators=n_estimators,
validation_fraction=0.2,
n_iter_no_change=5, tol=0.01,
random_state=0)
gb = ensemble.GradientBoostingClassifier(n_estimators=n_estimators,
random_state=0)
start = time.time()
gb.fit(X_train, y_train)
time_gb.append(time.time() - start)
start = time.time()
gbes.fit(X_train, y_train)
time_gbes.append(time.time() - start)
score_gb.append(gb.score(X_test, y_test))
score_gbes.append(gbes.score(X_test, y_test))
n_gb.append(gb.n_estimators_)
n_gbes.append(gbes.n_estimators_)
bar_width = 0.2
n = len(data_list)
index = np.arange(0, n * bar_width, bar_width) * 2.5
index = index[0:n]
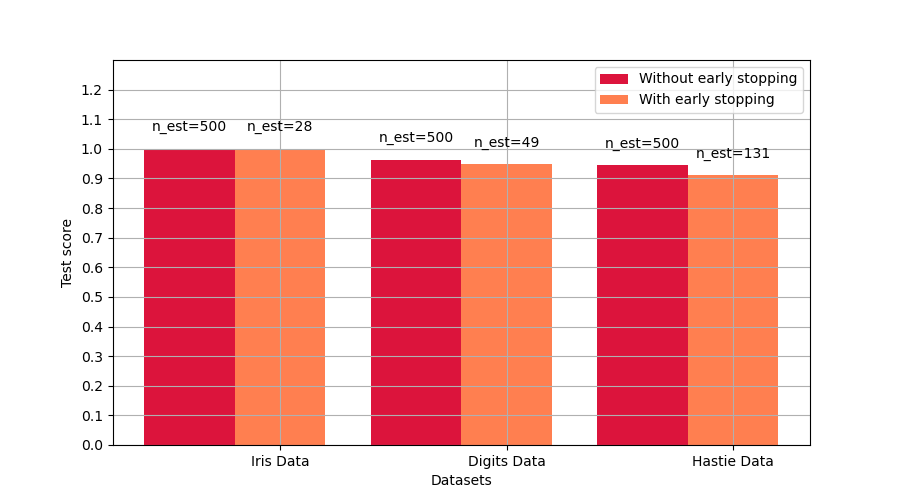
Compara las puntuaciones con y sin parada anticipada¶
plt.figure(figsize=(9, 5))
bar1 = plt.bar(index, score_gb, bar_width, label='Without early stopping',
color='crimson')
bar2 = plt.bar(index + bar_width, score_gbes, bar_width,
label='With early stopping', color='coral')
plt.xticks(index + bar_width, names)
plt.yticks(np.arange(0, 1.3, 0.1))
def autolabel(rects, n_estimators):
"""
Attach a text label above each bar displaying n_estimators of each model
"""
for i, rect in enumerate(rects):
plt.text(rect.get_x() + rect.get_width() / 2.,
1.05 * rect.get_height(), 'n_est=%d' % n_estimators[i],
ha='center', va='bottom')
autolabel(bar1, n_gb)
autolabel(bar2, n_gbes)
plt.ylim([0, 1.3])
plt.legend(loc='best')
plt.grid(True)
plt.xlabel('Datasets')
plt.ylabel('Test score')
plt.show()
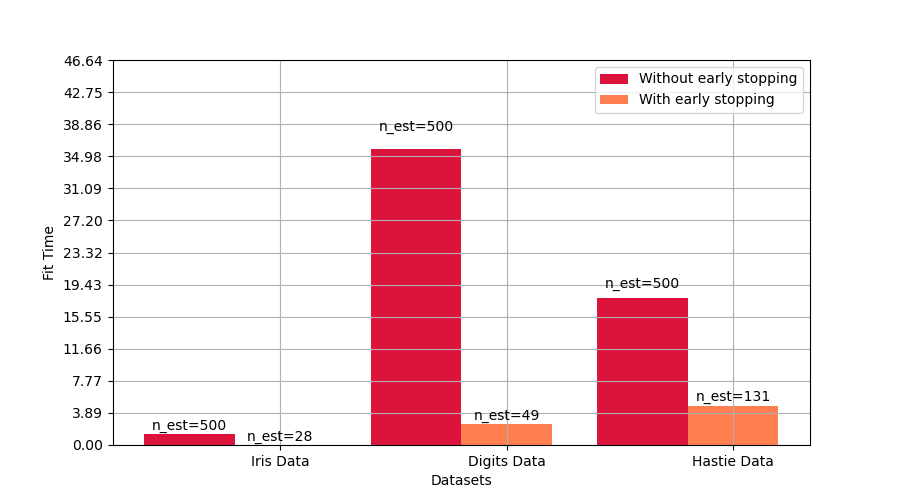
Compara los tiempos de ajuste con y sin parada anticipada¶
plt.figure(figsize=(9, 5))
bar1 = plt.bar(index, time_gb, bar_width, label='Without early stopping',
color='crimson')
bar2 = plt.bar(index + bar_width, time_gbes, bar_width,
label='With early stopping', color='coral')
max_y = np.amax(np.maximum(time_gb, time_gbes))
plt.xticks(index + bar_width, names)
plt.yticks(np.linspace(0, 1.3 * max_y, 13))
autolabel(bar1, n_gb)
autolabel(bar2, n_gbes)
plt.ylim([0, 1.3 * max_y])
plt.legend(loc='best')
plt.grid(True)
plt.xlabel('Datasets')
plt.ylabel('Fit Time')
plt.show()
Tiempo total de ejecución del script: (1 minutos 2.903 segundos)