Nota
Haz clic en aquí para descargar el código de ejemplo completo o para ejecutar este ejemplo en tu navegador a través de Binder
Comparación de la proyección arreglo 2D de LDA y PCA del conjunto de datos de Iris¶
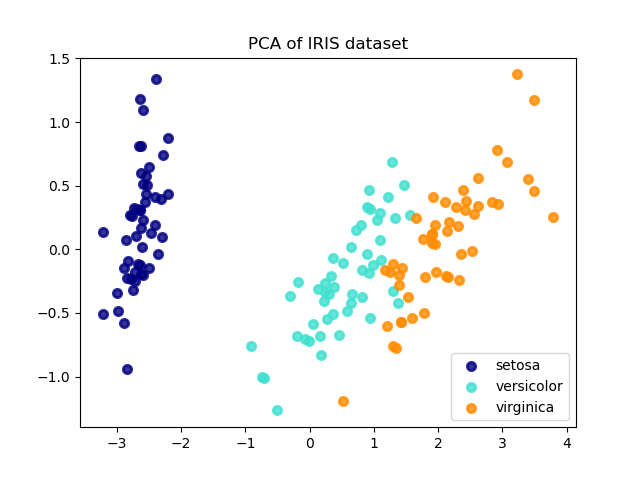
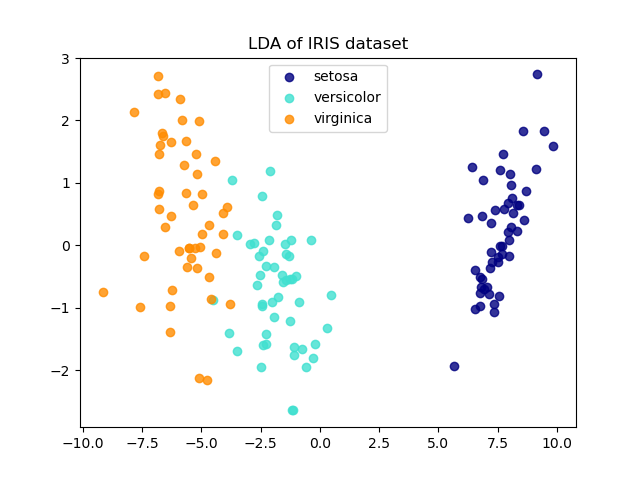
El conjunto de datos de Iris representa 3 tipos de flores de Iris (Setosa, Versicolor y Virginica) con 4 atributos: longitud del sépalo, anchura del sépalo, longitud del pétalo y anchura del pétalo.
El Análisis de Componentes Principales (Principal Component Analysis, PCA) aplicado a estos datos identifica la combinación de atributos (componentes principales, o direcciones en el espacio de características) que explican la mayor varianza de los datos. Aquí representamos las diferentes muestras en los 2 primeros componentes principales.
El Análisis Discriminante Lineal (LDA) trata de identificar los atributos que explican la mayor varianza entre las clases. En concreto, el LDA, a diferencia del PCA, es un método supervisado que utiliza etiquetas de clase conocidas.
Out:
explained variance ratio (first two components): [0.92461872 0.05306648]
print(__doc__)
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
iris = datasets.load_iris()
X = iris.data
y = iris.target
target_names = iris.target_names
pca = PCA(n_components=2)
X_r = pca.fit(X).transform(X)
lda = LinearDiscriminantAnalysis(n_components=2)
X_r2 = lda.fit(X, y).transform(X)
# Percentage of variance explained for each components
print('explained variance ratio (first two components): %s'
% str(pca.explained_variance_ratio_))
plt.figure()
colors = ['navy', 'turquoise', 'darkorange']
lw = 2
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(X_r[y == i, 0], X_r[y == i, 1], color=color, alpha=.8, lw=lw,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('PCA of IRIS dataset')
plt.figure()
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(X_r2[y == i, 0], X_r2[y == i, 1], alpha=.8, color=color,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('LDA of IRIS dataset')
plt.show()
Tiempo total de ejecución del script: ( 0 minutos 0.360 segundos)