Nota
Haz clic en aquí para descargar el código completo del ejemplo o para ejecutar este ejemplo en tu navegador a través de Binder
Reconocimiento de dígitos escritos a mano¶
Este ejemplo muestra cómo scikit-learn puede utilizarse para reconocer imágenes de dígitos escritos a mano, del 0 al 9.
print(__doc__)
# Author: Gael Varoquaux <gael dot varoquaux at normalesup dot org>
# License: BSD 3 clause
# Standard scientific Python imports
import matplotlib.pyplot as plt
# Import datasets, classifiers and performance metrics
from sklearn import datasets, svm, metrics
from sklearn.model_selection import train_test_split
Conjunto de datos de dígitos¶
El conjunto de datos de dígitos consiste en imágenes de 8x8 píxeles de dígitos. El atributo images del conjunto de datos almacena matrices de 8x8 de valores en escala de grises para cada imagen. Utilizaremos estos arreglos para visualizar las 4 primeras imágenes. El atributo target del conjunto de datos almacena el dígito que representa cada imagen y que se incluye en el título de los 4 gráficos siguientes.
Nota: si estuviéramos trabajando a partir de archivos de imagen (por ejemplo, archivos “png”), los cargaríamos utilizando matplotlib.pyplot.imread.
digits = datasets.load_digits()
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, label in zip(axes, digits.images, digits.target):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Training: %i' % label)

Clasificación¶
Para aplicar un clasificador a estos datos, tenemos que aplanar las imágenes, convirtiendo cada arreglo 2-D de valores en escala de grises de la forma (8, 8) en la forma (64,). Posteriormente, el conjunto de datos tendrá la forma (n_samples, n_features), donde n_samples es el número de imágenes y n_características es el número total de píxeles de cada imagen.
A continuación, podemos dividir los datos en subconjuntos de entrenamiento y de prueba y ajustar un clasificador de vectores de soporte a las muestras de entrenamiento. El clasificador ajustado puede utilizarse posteriormente para predecir el valor del dígito para las muestras del subconjunto de prueba.
# flatten the images
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Create a classifier: a support vector classifier
clf = svm.SVC(gamma=0.001)
# Split data into 50% train and 50% test subsets
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False)
# Learn the digits on the train subset
clf.fit(X_train, y_train)
# Predict the value of the digit on the test subset
predicted = clf.predict(X_test)
A continuación, visualizamos las 4 primeras muestras de prueba y mostramos su valor de dígito predicho en el título.
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, prediction in zip(axes, X_test, predicted):
ax.set_axis_off()
image = image.reshape(8, 8)
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title(f'Prediction: {prediction}')

classification_report construye un informe de texto que muestra las principales métricas de clasificación.
print(f"Classification report for classifier {clf}:\n"
f"{metrics.classification_report(y_test, predicted)}\n")
Out:
Classification report for classifier SVC(gamma=0.001):
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.99 0.97 0.98 91
2 0.99 0.99 0.99 86
3 0.98 0.87 0.92 91
4 0.99 0.96 0.97 92
5 0.95 0.97 0.96 91
6 0.99 0.99 0.99 91
7 0.96 0.99 0.97 89
8 0.94 1.00 0.97 88
9 0.93 0.98 0.95 92
accuracy 0.97 899
macro avg 0.97 0.97 0.97 899
weighted avg 0.97 0.97 0.97 899
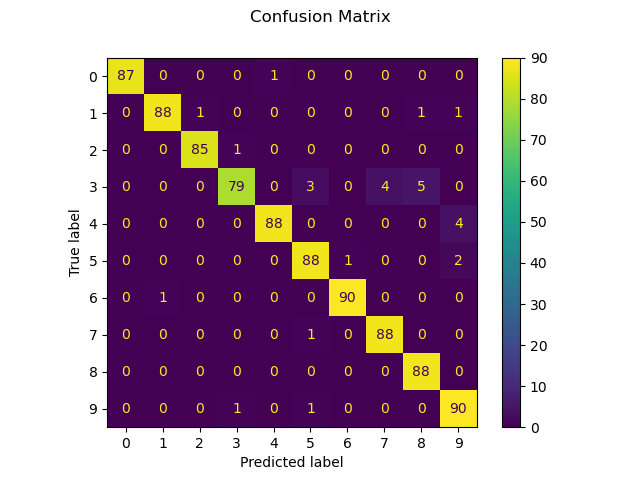
También podemos trazar una matriz de confusión de los valores de los dígitos verdaderos y los valores de los dígitos predichos.
disp = metrics.plot_confusion_matrix(clf, X_test, y_test)
disp.figure_.suptitle("Confusion Matrix")
print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()
Out:
Confusion matrix:
[[87 0 0 0 1 0 0 0 0 0]
[ 0 88 1 0 0 0 0 0 1 1]
[ 0 0 85 1 0 0 0 0 0 0]
[ 0 0 0 79 0 3 0 4 5 0]
[ 0 0 0 0 88 0 0 0 0 4]
[ 0 0 0 0 0 88 1 0 0 2]
[ 0 1 0 0 0 0 90 0 0 0]
[ 0 0 0 0 0 1 0 88 0 0]
[ 0 0 0 0 0 0 0 0 88 0]
[ 0 0 0 1 0 1 0 0 0 90]]
Tiempo total de ejecución del script: (0 minutos 0.683 segundos)