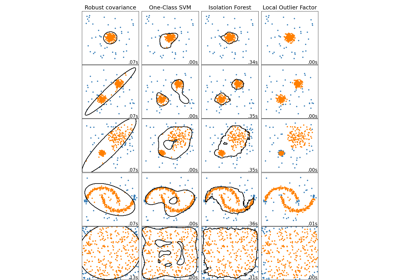
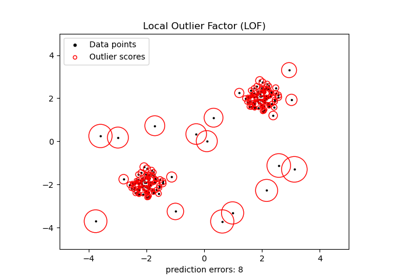
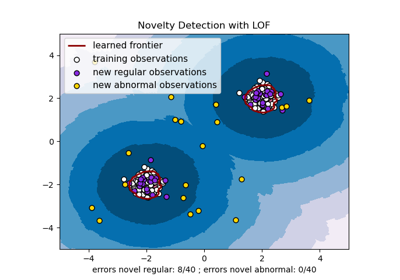
sklearn.neighbors.LocalOutlierFactor¶
- class sklearn.neighbors.LocalOutlierFactor¶
Detección no supervisada de valores atípicos mediante el factor local de valores atípicos (LOF)
La puntuación de anomalía de cada muestra se denomina Factor de Anomalía Local. Mide la desviación local de la densidad de una muestra dada con respecto a sus vecinos. Es local en el sentido de que el valor de la anomalía depende de lo aislado que esté el objeto con respecto al vecindario circundante. Más concretamente, la localidad viene dada por los k vecinos más cercanos, cuya distancia se utiliza para estimar la densidad local. Comparando la densidad local de una muestra con las densidades locales de sus vecinos, se pueden identificar las muestras que tienen una densidad sustancialmente menor que sus vecinos. Estas se consideran valores atípicos.
Nuevo en la versión 0.19.
- Parámetros
- n_neighborsentero, default=20
Número de vecinos a usar por defecto para
kneighborsconsultas. Si n_neighbors es mayor que el número de muestras proporcionadas, todas las muestras serán usadas.- algorithm{“auto”, “ball_tree”, “kd_tree”, “brute”}, default=”auto”
Algoritmo usado para calcular los vecinos más cercanos:
“ball_tree” usará
BallTree“kd_tree” usará
KDTree“brute” usará una búsqueda de fuerza bruta.
“auto” intentará decidir el algoritmo más apropiado basado en los valores pasados al método
fit.
Nota: el ajuste en la entrada dispersa anulará el ajuste de este parámetro, utilizando la fuerza bruta.
- leaf_sizeentero, default=30
Tamaño de la hoja que se pasa a
BallTreeoKDTree. Esto puede afectar a la velocidad de construcción y consulta, así como a la memoria necesaria para almacenar el árbol. El valor óptimo depende de la naturaleza del problema.- metriccadena de caracteres o invocable, default=»minkowski”
métrica utilizada para el cálculo a distancia. Cualquier métrica de scikit-learn o scipy.spatial.distance puede ser usada.
Si la métrica es «precomputed», se supone que X es una matriz de distancia y debe ser cuadrada. X puede ser una matriz dispersa, en cuyo caso sólo los elementos «no nulos» pueden considerarse vecinos.
Si la métrica es una función invocable, se llama a cada par de instancias (filas) y se registra el valor resultante. El invocable debe tomar dos arreglos como entrada y devolver un valor que indique la distancia entre ellos. Esto funciona para las métricas de Scipy, pero es menos eficiente que pasar el nombre de la métrica como una cadena.
Valores válidos para la métrica son:
de scikit-learn: [“cityblock”, “cosine”, “euclidean”, “l1”, “l2”, “manhattan”]
de scipy.spatial.distance: [“braycurtis”, “canberra”, “chebyshev”, “correlation”, “dice”, “hamming”, “jaccard”, “kulsinski”, “mahalanobis”, “minkowski”, “rogerstanimoto”, “russellrao”, “seuclidean”, “sokalmichener”, “sokalsneath”, “sqeuclidean”, “yule”]
Consulta la documentación de scipy.spatial.distance para obtener detalles sobre estas métricas: https://docs.scipy.org/doc/scipy/reference/spatial.distance.html
- pentero, default=2
Parámetro para la métrica de Minkowski de
sklearn.metrics.pairwise.pairwise_distances. Cuando p = 1, esto es equivalente a usar manhattan_distance (l1), y euclidean_distance (l2) para p = 2. Para una p arbitraria, se usa minkowski_distance (l_p).- metric_paramsdict, default=None
Argumentos adicionales de palabras clave para la función métrica.
- contamination“auto” o flotante, default=”auto”
La cantidad de contaminación del conjunto de datos, es decir, la proporción de los atajos en el conjunto de datos. Cuando se ajusta esto se utiliza para definir el umbral en los valores de las muestras.
si “auto”, el umbral se determina como en el artículo original,
si un flotante, la contaminación debería estar en el rango [0, 0.5].
Distinto en la versión 0.22: El valor predeterminado de
contaminacióncambió de 0.1 a'auto'.- noveltybooleano, default=False
Por defecto, LocalOutlierFactor sólo está pensado para ser utilizado para la detección atmosférica (novelty=False). Establecer novelty a True si desea utilizar LocalOutlierFactor para la detección novelty. En este caso, ten en cuenta que sólo debe usar predict, decision_function y score_samples en nuevos datos no vistos y no en el conjunto de entrenamientos.
Nuevo en la versión 0.20.
- n_jobsentero, default=None
El número de trabajos paralelos a ejecutar para la búsqueda de vecinos.
Nonesignifica 1 a menos que en unjoblib. contexto arallel_backend.-1significa usar todos los procesadores. Ver Glosario para más detalles.
- Atributos
- negative_outlier_factor_ndarray de forma (n_samples,)
El LOF opuesto de las muestras de entrenamiento. Cuanto más alto, más normal. Los valores típicos tienden a tener un valor de LOF cercana a 1 (
negative_outlier_factor_cercano a -1), mientras que los valores atípìcos tienden a tener un valor de LOF mayor.El factor local de valores atípicos (LOF) de una muestra capta su supuesto «grado de anormalidad». Es la media de la razón entre la densidad de accesibilidad local de una muestra y las de sus k vecinos más cercanos.
- n_neighbors_entero
El número real de vecinos usados para
kneighborsconsultas.- offset_flotante
Desplazamiento utilizado para obtener etiquetas binarias a partir de las puntuaciones brutas. Las observaciones que tienen un factor_de_extremo_negativo menor que
offset_se detectan como anormales. El desplazamiento se fija en -1,5 (los valores típicos se sitúan en torno a -1), excepto cuando se proporciona un parámetro de contaminación distinto de «auto». En ese caso, el desplazamiento se define de forma que se obtiene el número esperado de valores atípicos en el entrenamiento.Nuevo en la versión 0.20.
- effective_metric_cadena
La métrica efectiva utilizada para el cálculo a distancia.
- effective_metric_params_dict
Los argumentos adicionales efectivos de la palabra clave para la función métrica.
- n_samples_fit_entero
Es el número de muestras en los datos ajustados.
Referencias
- 1
Breunig, M. M., Kriegel, H. P., Ng, R. T., & Sander, J. (2000, May). LOF: identifying density-based local outliers. In ACM sigmod record.
Ejemplos
>>> import numpy as np >>> from sklearn.neighbors import LocalOutlierFactor >>> X = [[-1.1], [0.2], [101.1], [0.3]] >>> clf = LocalOutlierFactor(n_neighbors=2) >>> clf.fit_predict(X) array([ 1, 1, -1, 1]) >>> clf.negative_outlier_factor_ array([ -0.9821..., -1.0370..., -73.3697..., -0.9821...])
Métodos
Ajusta el detector local de valores atípicos del conjunto de datos de entrenamiento.
Obtiene los parámetros de este estimador.
Encuentra a los K-vecinos de un punto.
Calcula el grafo (ponderado) de k-vecinos para los puntos de X
Establece los parámetros de este estimador.
- property decision_function¶
Desplazamiento opuesto al Factor Local de Desviación de X.
Más grande es mejor, es decir, los valores grandes corresponden a los valores típicos.
Sólo disponible para la detección de novedades (cuando novelty se establece en True). El desplazamiento permite un umbral cero para ser un valor atípico. El argumento X se supone que contiene datos nuevos: si X contiene un punto del entrenamiento, se considera el posterior en su propio vecindario. Además, las muestras en X no se consideran en el vecindario de ningún punto.
- Parámetros
- Xarray-like de forma (n_samples, n_features)
La muestra o muestras de consulta para calcular el factor local de valores atípicos con respecto a las muestras de entrenamiento.
- Devuelve
- shifted_opposite_lof_scoresndarray de forma (n_samples,)
El opuesto desplazado del Factor de Anomalía Local de cada muestra de entrada. Cuanto más bajo, más anormal. Las puntuaciones negativas representan valores atípicos, y las positivas representan valores atípicos.
- fit()¶
Ajusta el detector local de valores atípicos del conjunto de datos de entrenamiento.
- Parámetros
- X{array-like, sparse matrix} de forma (n_samples, n_features) o (n_samples, n_samples) si metric=”precomputed”
Datos de entrenamiento.
- yIgnorado
No se utiliza, está presente para la coherencia de la API por convención.
- Devuelve
- selfLocalOutlierFactor
El detector de factores atípicos locales ajustado.
- property fit_predict¶
Ajusta el modelo al conjunto de entrenamiento X y devuelve las etiquetas.
**No disponible para la detección de novedades (cuando la novedad se establece como True). **La etiqueta es 1 para un valor típico y -1 para un valor atípico según el valor LOF y el parámetro de contaminación.
- Parámetros
- Xarray-like de forma (n_samples, n_features), default=None
La muestra o muestras de consulta para calcular el factor local de valores atípicos con respecto a las muestras de entrenamiento.
- yIgnorado
No se utiliza, está presente para la coherencia de la API por convención.
- Devuelve
- is_inlierndarray de forma (n_samples,)
Devuelve -1 para las anomalías/atípicos y +1 para los típicos.
- get_params()¶
Obtiene los parámetros de este estimador.
- Parámetros
- deepbooleano, default=True
Si es True, devolverá los parámetros para este estimador y los sub objetos contenidos que son estimadores.
- Devuelve
- paramsdict
Nombres de parámetros mapeados a sus valores.
- kneighbors()¶
Encuentra a los K-vecinos de un punto.
Devuelve los índices y las distancias a los vecinos de cada punto.
- Parámetros
- Xarray-like, forma (n_queries, n_features), o (n_queries, n_indexed) si metric == “precomputed”, default=None
El punto o puntos de la consulta. Si no se proporciona, se devuelven los vecinos de cada punto indexado. En este caso, el punto de consulta no se considera su propio vecino.
- n_neighborsentero, default=None
Número de vecinos necesarios para cada muestra. El valor predeterminado es el que se pasa al constructor.
- return_distancebooleano, default=True
Si se devuelven o no las distancias.
- Devuelve
- neigh_distndarray de forma (n_queries, n_neighbors)
Un arreglo que representa las longitudes de los puntos, sólo presente si return_distance=True
- neigh_indndarray de forma (n_queries, n_neighbors)
Indices de los puntos más cercanos en la matriz de la población.
Ejemplos
En el siguiente ejemplo, construimos una clase NearestNeighbors a partir de un arreglo que representa nuestro conjunto de datos y preguntamos cuál es el punto más cercano a [1,1,1]
>>> samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=1) >>> neigh.fit(samples) NearestNeighbors(n_neighbors=1) >>> print(neigh.kneighbors([[1., 1., 1.]])) (array([[0.5]]), array([[2]]))
Como puedes ver, devuelve [[0.5]], y [[2]], lo que significa que el elemento está a la distancia 0.5 y es el tercer elemento de las muestras (los índices empiezan en 0). También puede consultar varios puntos:
>>> X = [[0., 1., 0.], [1., 0., 1.]] >>> neigh.kneighbors(X, return_distance=False) array([[1], [2]]...)
- kneighbors_graph()¶
Calcula el grafo (ponderado) de k-vecinos para los puntos de X
- Parámetros
- Xarray-like de forma (n_queries, n_features), o (n_queries, n_indexed) si metric == “precomputed”, default=None
El punto o puntos de la consulta. Si no se proporciona, se devuelven los vecinos de cada punto indexado. En este caso, el punto de consulta no se considera su propio vecino. Para
metric='precomputed'la forma debe ser (n_queries, n_indexed). En caso contrario, la forma debe ser (n_queries, n_features).- n_neighborsentero, default=None
Número de vecinos para cada muestra. El valor predeterminado es el que se pasa al constructor.
- mode{“connectivity”, “distance”}, default=”connectivity”
Tipo de matriz devuelta: “connectivity” devolverá la matriz de conectividad con unos y ceros, en “distance” los bordes son la distancia euclidiana entre puntos.
- Devuelve
- Amatriz dispersa de forma (n_queries, n_samples_fit)
n_samples_fites el número de muestras en los datos ajustadosA[i, j]se asigna el peso del borde que conectaiconj. La matriz tiene el formato CSR.
Ver también
Ejemplos
>>> X = [[0], [3], [1]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=2) >>> neigh.fit(X) NearestNeighbors(n_neighbors=2) >>> A = neigh.kneighbors_graph(X) >>> A.toarray() array([[1., 0., 1.], [0., 1., 1.], [1., 0., 1.]])
- property predict¶
Predice las etiquetas (1 típico, -1 atípico) de X de acuerdo al LOF.
**Sólo disponible para la detección de novedades (cuando la novedad se establece como True). ** Este método permite generalizar la predicción a nuevas observaciones (no en el conjunto de entrenamiento).
- Parámetros
- Xarray-like de forma (n_samples, n_features)
La muestra o muestras de consulta para calcular el factor local de valores atípicos con respecto a las muestras de entrenamiento.
- Devuelve
- is_inlierndarray de forma (n_samples,)
Devuelve -1 para las anomalías/atípicos y +1 para los típicos.
- property score_samples¶
Opuesto al Factor Local de Excedencia de X.
Es lo contrario, ya que lo más grande es mejor, es decir, los valores grandes corresponden a los valores típicos.
**Sólo disponible para la detección de novedades (cuando novelty se establece como True). **Se supone que el argumento X contiene datos nuevos: si X contiene un punto de entrenamiento, se considera el posterior en su propio vecindario. Además, las muestras en X no se consideran en el vecindario de ningún punto. El valor de las muestras en los datos de entrenamiento está disponible al considerar el atributo
negative_outlier_factor_.- Parámetros
- Xarray-like de forma (n_samples, n_features)
La muestra o muestras de consulta para calcular el factor local de valores atípicos con respecto a las muestras de entrenamiento.
- Devuelve
- opposite_lof_scoresndarray de forma (n_samples,)
Lo contrario del Factor de Anomalía Local de cada muestra de entrada. Cuanto más bajo, más anormal.
- set_params()¶
Establece los parámetros de este estimador.
El método funciona tanto con estimadores simples como en objetos anidados (como
Pipeline). Estos últimos tienen parámetros de la forma<component>__<parameter>para que sea posible actualizar cada componente de un objeto anidado.- Parámetros
- **paramsdict
Parámetros del estimador.
- Devuelve
- selfinstancia del estimador
Instancia de estimador.