Nota
Haz clic aquí para descargar el código completo del ejemplo o para ejecutar este ejemplo en tu navegador a través de Binder
Clasificación multietiqueta¶
Este ejemplo simula un problema de clasificación de documentos multietiqueta. El conjunto de datos se genera aleatoriamente basado en el siguiente proceso:
elegir el número de etiquetas: n ~ Poisson(n_labels)
n veces, elegir una clase c: c ~ Multinomial(theta)
elegir la longitud del documento: k ~ Poisson(length)
k veces, elegir una palabra: w ~ Multinomial(theta_c)
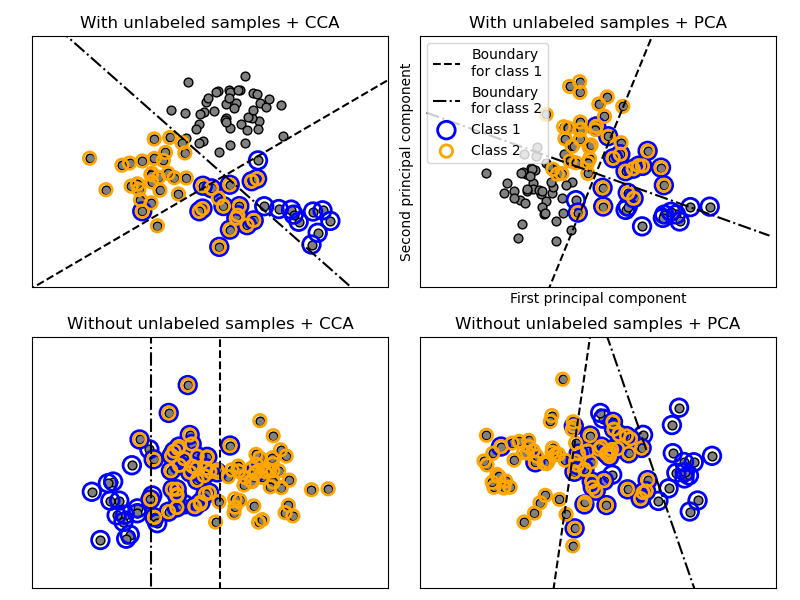
En el proceso anterior, se utiliza el muestreo de rechazo para asegurarse de que n sea mayor que 2, y que la longitud del documento nunca sea cero. Asimismo, rechazamos las clases que ya han sido elegidas. Los documentos que se asignan a ambas clases se representan rodeados de dos círculos de color.
La clasificación se realiza proyectando a los dos primeros componentes principales encontrados por PCA y CCA con fines de visualización, seguido de la utilización del metaclasificador OneVsRestClassifier usando dos SVC con kernels lineales para aprender un modelo discriminativo para cada clase. Ten en cuenta que el PCA se utiliza para realizar una reducción de dimensionalidad no supervisada, mientras que el CCA se utiliza para realizar una supervisada.
Nota: en el gráfico, «unlabeled samples» no significa que no conozcamos las etiquetas (como en el aprendizaje semisupervisado), sino que las muestras simplemente no tienen una etiqueta.
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_multilabel_classification
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn.cross_decomposition import CCA
def plot_hyperplane(clf, min_x, max_x, linestyle, label):
# get the separating hyperplane
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(min_x - 5, max_x + 5) # make sure the line is long enough
yy = a * xx - (clf.intercept_[0]) / w[1]
plt.plot(xx, yy, linestyle, label=label)
def plot_subfigure(X, Y, subplot, title, transform):
if transform == "pca":
X = PCA(n_components=2).fit_transform(X)
elif transform == "cca":
X = CCA(n_components=2).fit(X, Y).transform(X)
else:
raise ValueError
min_x = np.min(X[:, 0])
max_x = np.max(X[:, 0])
min_y = np.min(X[:, 1])
max_y = np.max(X[:, 1])
classif = OneVsRestClassifier(SVC(kernel='linear'))
classif.fit(X, Y)
plt.subplot(2, 2, subplot)
plt.title(title)
zero_class = np.where(Y[:, 0])
one_class = np.where(Y[:, 1])
plt.scatter(X[:, 0], X[:, 1], s=40, c='gray', edgecolors=(0, 0, 0))
plt.scatter(X[zero_class, 0], X[zero_class, 1], s=160, edgecolors='b',
facecolors='none', linewidths=2, label='Class 1')
plt.scatter(X[one_class, 0], X[one_class, 1], s=80, edgecolors='orange',
facecolors='none', linewidths=2, label='Class 2')
plot_hyperplane(classif.estimators_[0], min_x, max_x, 'k--',
'Boundary\nfor class 1')
plot_hyperplane(classif.estimators_[1], min_x, max_x, 'k-.',
'Boundary\nfor class 2')
plt.xticks(())
plt.yticks(())
plt.xlim(min_x - .5 * max_x, max_x + .5 * max_x)
plt.ylim(min_y - .5 * max_y, max_y + .5 * max_y)
if subplot == 2:
plt.xlabel('First principal component')
plt.ylabel('Second principal component')
plt.legend(loc="upper left")
plt.figure(figsize=(8, 6))
X, Y = make_multilabel_classification(n_classes=2, n_labels=1,
allow_unlabeled=True,
random_state=1)
plot_subfigure(X, Y, 1, "With unlabeled samples + CCA", "cca")
plot_subfigure(X, Y, 2, "With unlabeled samples + PCA", "pca")
X, Y = make_multilabel_classification(n_classes=2, n_labels=1,
allow_unlabeled=False,
random_state=1)
plot_subfigure(X, Y, 3, "Without unlabeled samples + CCA", "cca")
plot_subfigure(X, Y, 4, "Without unlabeled samples + PCA", "pca")
plt.subplots_adjust(.04, .02, .97, .94, .09, .2)
plt.show()
Tiempo total de ejecución del script: (0 minutos 0.456 segundos)