Nota
Haz clic en aquí para descargar el código de ejemplo completo o para ejecutar este ejemplo en tu navegador a través de Binder
AdaBoost de dos clases¶
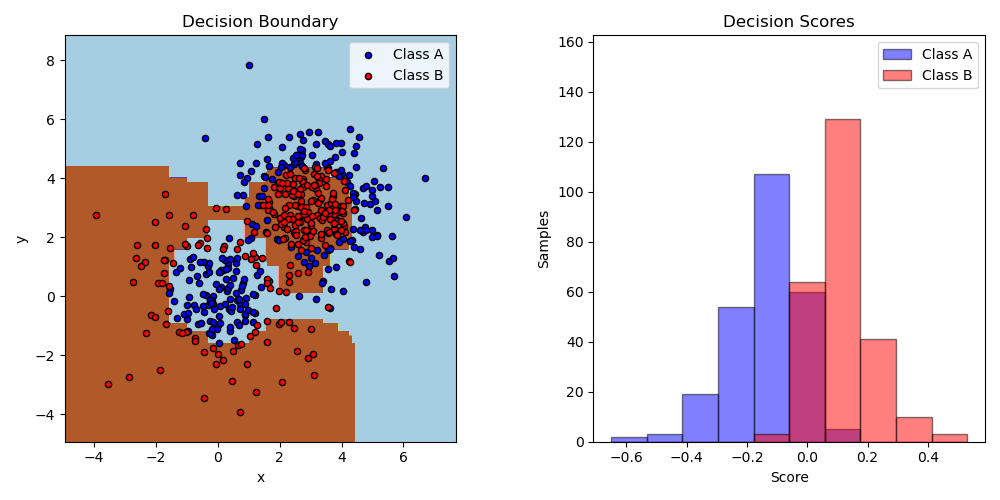
Este ejemplo ajusta un muñón de decisión AdaBoosted en un conjunto de datos de clasificación no linealmente separable compuesto por dos conglomerados de «cuantiles gaussianos» (ver sklearn.datasets.make_gaussian_quantiles) y traza el límite de decisión y las puntuaciones de decisión. Las distribuciones de las puntuaciones de decisión se muestran por separado para las muestras de la clase A y B. La etiqueta de clase predicha para cada muestra está determinada por el signo de la puntuación de decisión. Las muestras con puntuaciones de decisión superiores a cero se clasifican como B, y en caso contrario se clasifican como A. La magnitud de una puntuación de decisión determina el grado de similitud con la etiqueta de clase predicha. Además, se puede construir un nuevo conjunto de datos que contenga una pureza (purity) deseada de la clase B, por ejemplo, seleccionando sólo las muestras con una puntuación de decisión superior a algún valor.
print(__doc__)
# Author: Noel Dawe <noel.dawe@gmail.com>
#
# License: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
# Construct dataset
X1, y1 = make_gaussian_quantiles(cov=2.,
n_samples=200, n_features=2,
n_classes=2, random_state=1)
X2, y2 = make_gaussian_quantiles(mean=(3, 3), cov=1.5,
n_samples=300, n_features=2,
n_classes=2, random_state=1)
X = np.concatenate((X1, X2))
y = np.concatenate((y1, - y2 + 1))
# Create and fit an AdaBoosted decision tree
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1),
algorithm="SAMME",
n_estimators=200)
bdt.fit(X, y)
plot_colors = "br"
plot_step = 0.02
class_names = "AB"
plt.figure(figsize=(10, 5))
# Plot the decision boundaries
plt.subplot(121)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
Z = bdt.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.axis("tight")
# Plot the training points
for i, n, c in zip(range(2), class_names, plot_colors):
idx = np.where(y == i)
plt.scatter(X[idx, 0], X[idx, 1],
c=c, cmap=plt.cm.Paired,
s=20, edgecolor='k',
label="Class %s" % n)
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.legend(loc='upper right')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Decision Boundary')
# Plot the two-class decision scores
twoclass_output = bdt.decision_function(X)
plot_range = (twoclass_output.min(), twoclass_output.max())
plt.subplot(122)
for i, n, c in zip(range(2), class_names, plot_colors):
plt.hist(twoclass_output[y == i],
bins=10,
range=plot_range,
facecolor=c,
label='Class %s' % n,
alpha=.5,
edgecolor='k')
x1, x2, y1, y2 = plt.axis()
plt.axis((x1, x2, y1, y2 * 1.2))
plt.legend(loc='upper right')
plt.ylabel('Samples')
plt.xlabel('Score')
plt.title('Decision Scores')
plt.tight_layout()
plt.subplots_adjust(wspace=0.35)
plt.show()
Tiempo total de ejecución del script: (0 minutos 2.797 segundos)